- @m0_63947499
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
做 Agent 的都知道,让大模型读文档,第一步是"把纸变成字"。这一步看起来很简单——OCR 发展了二十年,字符识别率早就过了 95%。但是当你拿到一张真实的财务底稿:合并单元格里藏着父子隶属关系,跨页长表的续接信号弱得像页脚的水印,嵌套表格里套着另一张子表——OCR 把每个字都认对了,但输出的字符串像被洗牌机搅过,列对不上、行挂错、表头飘到了正文里。Agent 拿到这堆"无主数字",引用时错得

所有Agent都在卷"脑子",我开始思考——如果AI有一副身体,交互会变成什么样?
所有Agent都在卷"脑子",我开始思考——如果AI有一副身体,交互会变成什么样?
相信很多开发者和数码爱好者都遇到过这样的问题:花几千块搭建了 NAS 服务器,部署了 Jellyfin 影音库、qBittorrent 下载器、Docker 容器集群,结果一离开局域网就彻底无法访问;想要远程调试家里的开发板、管理软路由,却被运营商的对称 NAT 和无公网 IP 限制;尝试过多种远程连接方案,要么配置复杂需要编写大量命令,要么速度缓慢、限制众多,要么存在数据安全隐患。

做AI这行久了,我对"理解模型看不懂图、生成模型画不对意思"这种割裂早就见怪不怪了。视觉理解模型(比如CLIP、传统VLM)看图说话一把好手,但让它画张图就歇菜;图像生成模型(比如Stable Diffusion)画出来的东西确实漂亮,可你让它理解复杂语义,它就抓瞎。"理解"和"生成"之间这道鸿沟,一直是多模态AI最头疼的问题。
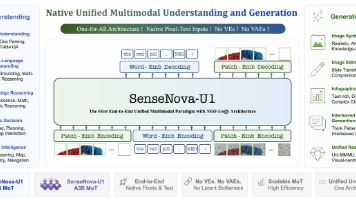
做AI这行久了,我对"理解模型看不懂图、生成模型画不对意思"这种割裂早就见怪不怪了。视觉理解模型(比如CLIP、传统VLM)看图说话一把好手,但让它画张图就歇菜;图像生成模型(比如Stable Diffusion)画出来的东西确实漂亮,可你让它理解复杂语义,它就抓瞎。"理解"和"生成"之间这道鸿沟,一直是多模态AI最头疼的问题。
国产数据库工具的竞争,正在从基础客户端能力转向完整数据工作平台能力。过去,工具只要能连接数据库、执行 SQL、查看表数据,就可以满足一部分开发需求;现在,企业更关心工具是否可本地运行、是否可跨平台交付、是否支持审计、是否能沉淀文档、是否能接入企业自有模型,以及是否能把重复工作自动化。
问题一:海量视频数据实时处理能力不足解决方案:基于CANN模板库快速开发高性能预处理、特征提取算子,模板内置的tiling优化与并行计算能力提升内存访问效率,结合分布式通信实现多摄像头数据并行处理。效果:系统可实时处理1200路720P或600路1080P视频流,异常事件预警响应时间从3秒缩短至0.6秒,处理能力提升400%,完全满足大型城市监控中心的海量数据处理需求。问题二:AI开发门槛高,人才
本次小模型迁移性能调优实战,从最初的性能衰退到最终的超越原平台性能,整个过程充满了技术挑战和发现。最关键的是,我们打破了直觉的误导,通过科学的Profiling分析找到了真正的性能瓶颈。目前CANN的迭代速度很快,建议大家在迁移时如果遇到性能瓶颈,不要死磕代码逻辑,先跑一遍Profiler,大概率能帮你省下几天排查时间。如果常规手段搞不定,试试Torchair或者MindIE这种针对性的推理后端,
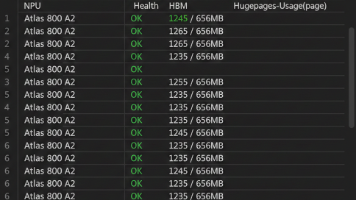
然而,随着 AI 算力需求的指数级增长,算力供应的多元化已成为行业共识。华为昇腾(Ascend)系列 AI 处理器,特别是 Atlas 800 A2(搭载 Ascend 910B 芯片)系列,凭借其在 FP16/BF16 混合精度计算上的强劲性能,逐渐成为国产化算力集群的首选。由于 vLLM 主干代码迭代极快,且部分 CUDA 语义(如 CUDA Graph)无法直接映射到 NPU 的 ACL G