




- @m0_63537602
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
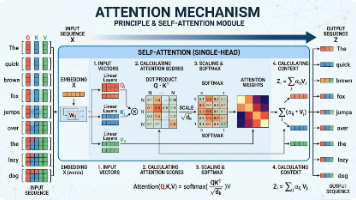
摘要:本文深入浅出地解析注意力机制的核心原理与应用,特别强调训练(model.train())与推理(model.eval())阶段的差异。通过生活化类比(如鸡尾酒会效应、阅读标注、拍照对焦)直观阐释注意力机制如何实现"选择性关注"。专业解析部分详细拆解缩放点积注意力的计算流程,并指出训练阶段需学习权重分配规则并启用正则化,而推理阶段则固定规则确保输出稳定。最后提供可直接运行的
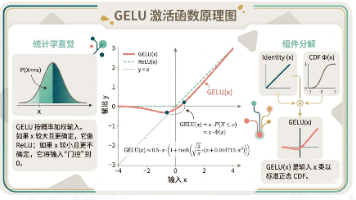
摘要:GELU(高斯误差线性单元)已成为大模型时代的核心激活函数,凭借其平滑非线性、梯度稳定等特性,全面替代ReLU成为Transformer、GPT等主流模型的标准配置。本文通过通俗化视角解析GELU工作原理,提供与ReLU对齐的PyTorch实现代码,并详细阐述其在大模型训练中的优势。实验表明,GELU在保持ReLU优点的同时解决了神经元死亡等问题,是深度学习模型开发的首选激活函数。
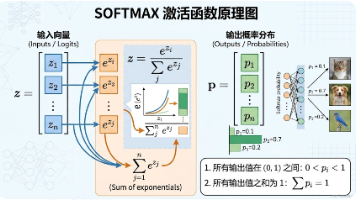
Softmax激活函数在多分类任务中的应用 摘要:Softmax是深度学习多分类任务的核心激活函数,可将神经网络输出的原始分数转换为概率分布。本文介绍了Softmax的基本原理、数学公式和数值稳定性优化方法,并提供了NumPy、PyTorch和TensorFlow三种实现方式。通过数值示例和代码演示,展示了Softmax如何将模型输出转换为直观的概率值,同时保持类别间的相对顺序。文章还特别强调了实
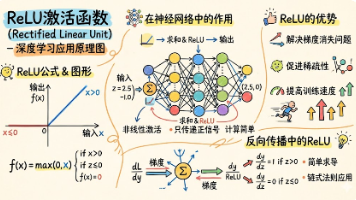
深度学习中的ReLU激活函数因其简单高效而广受欢迎。本文从新手角度详细解析ReLU的核心原理、数学公式和关键特性,重点介绍其在神经网络中的实际应用。文章包含常见问题解决方案(如死亡ReLU问题),并提供NumPy、PyTorch和TensorFlow/Keras的多框架实现代码,以及一个完整的神经网络实战案例。ReLU通过"留正去负"的简单逻辑,有效解决线性模型的局限性,同时避
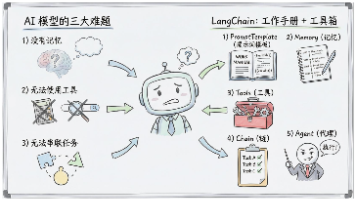
摘要:LangChain是一个开源的大模型应用开发框架,通过组件化设计解决大模型在记忆、工具调用和任务编排上的痛点。它将大模型与外部资源(如文档、工具、数据库)无缝连接,使开发者能快速构建复杂LLM应用。核心组件包括Models(模型接口)、Prompts(指令模板)、Chains(任务流程)、Memory(对话记忆)、Tools(外部工具)和Agents(自主决策)。本文结合生活化类比和专业解析
LoRA技术摘要 LoRA(低秩适配)是大模型参数高效微调(PEFT)的核心方案,通过低秩矩阵分解解决传统微调面临的三大痛点:1)全量微调显存爆炸问题;2)Adapter推理延迟问题;3)Prompt Tuning效果不足问题。其核心原理是利用预训练权重更新的低秩特性,冻结原模型参数,仅注入可训练的低秩矩阵对(AB),实现仅调整0.1%-1%参数就能达到接近全量微调的效果。 关键技术特点包括: 数