




- @m0_61879647
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
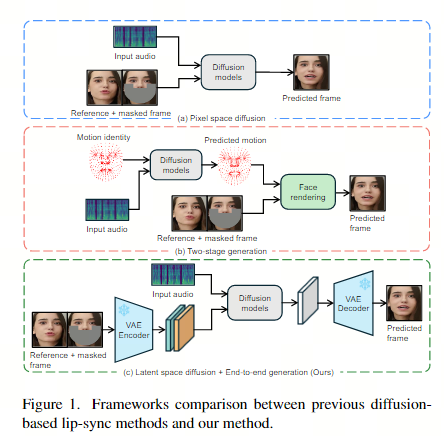
视频+音频->视频口型同步更像是一个视频到视频的编辑框架,需要保持嘴巴以外的区域与输入视频一致图像+音频->视频音频驱动人像动画更像是一个图像到视频的动画框架,可以改变头部的运动,甚至面部表情,整体框架的差异导致了唇形同步:Wav2Lip、Diff2LipMuseTalkMyTalk音频驱动的肖像动画:EMO、HalloEchoMimicVASA-1DreamTalkSadTalker。
我们介绍使用ms-swift对deepseek-ai/Janus-Pro-7B进行微调(注意:目前只支持图像理解的训练而不支持图像生成)。这里,我们将展示可运行的微调demo,并给出自定义数据集的格式。conda create -n swift #创建虚拟环境。如果要使用自定义数据集进行训练,你可以参考以下格式,并指定。在开始微调之前,请确保您的环境已准备妥当。微调完成,保存到output。是一个
通过简化输入建模、优化扩散架构与采样策略,实现高效且高质量的非自回归语音合成。一个基于E2 TTS模型的模型,通过ConvNeXt文本建模DiT架构轻量化与动态采样策略,解决了传统非自回归TTS的收敛慢、对齐差、推理效率低等痛点,实现了高效、鲁棒的语音合成。
视频+音频->视频口型同步更像是一个视频到视频的编辑框架,需要保持嘴巴以外的区域与输入视频一致图像+音频->视频音频驱动人像动画更像是一个图像到视频的动画框架,可以改变头部的运动,甚至面部表情,整体框架的差异导致了唇形同步:Wav2Lip、Diff2LipMuseTalkMyTalk音频驱动的肖像动画:EMO、HalloEchoMimicVASA-1DreamTalkSadTalker。