- @m0_57689625
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
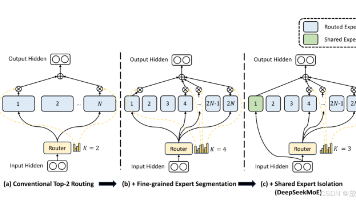
研究动机:这篇文章主要讲的是如何让大型AI模型变得更聪明、更省电。就像我们人类有不同领域的专家(比如医生、工程师、厨师)一样,AI模型内部也可以分成很多“小专家”。传统的方法有点像每次只请几个大专家来解决问题,但这些大专家可能懂的东西有重复,效率不高。核心贡献:1、细粒度专家分割技术将原N个专家细分为m×N个更小的专家单元,每次激活m×K个单元。优势:增强专家组合的灵活性,促进知识聚焦,减少专家间
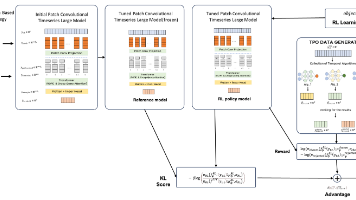
《京东提出时间序列大模型PCLTM与TPO强化学习框架》研究针对现有时间序列模型在扩展性和泛化能力上的不足,提出创新解决方案。通过构建包含2100亿数据点的大型数据集并建立严格的质量控制标准,提出基于补丁卷积的PCLTM模型处理复杂时序依赖关系。首次设计Time-series Policy Optimization(TPO)强化学习框架,利用算法自动生成预测对比对代替人工标注,实现时间序列模型与专
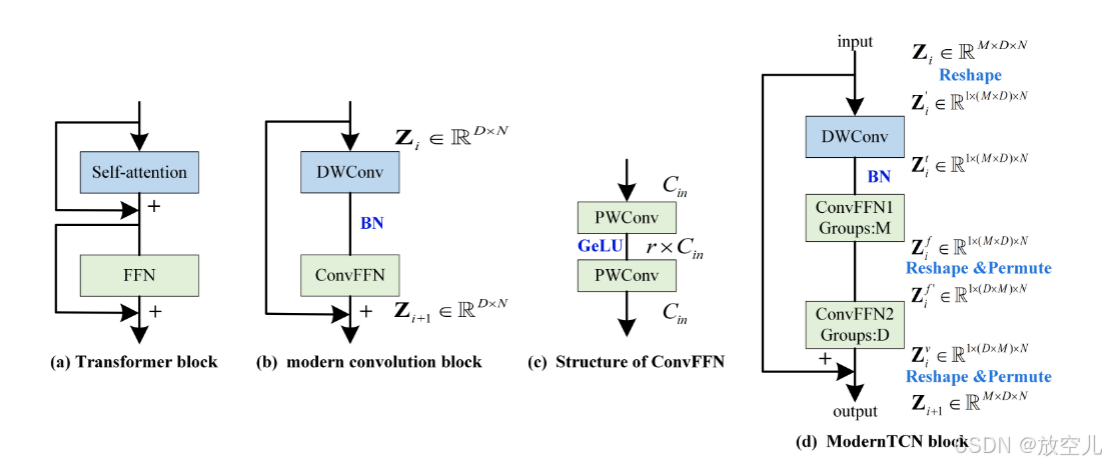
基于Transformer 及 MLP 模型在时间序列分析中迅速崛起并占据主导,卷积在时间序列任务中因性能欠佳而势头渐弱。探讨如何在时间序列分析中更好地利用卷积,使卷积重回该领域。对传统 TCN 进行现代化改进,使其更适用于时间序列任务,提出 ModernTCN,在五个主流时间序列分析任务中达到先进水平,同时保持卷积模型的效率优势,揭示 ModernTCN 具有更大的有效感受野,能更好地发挥卷积在
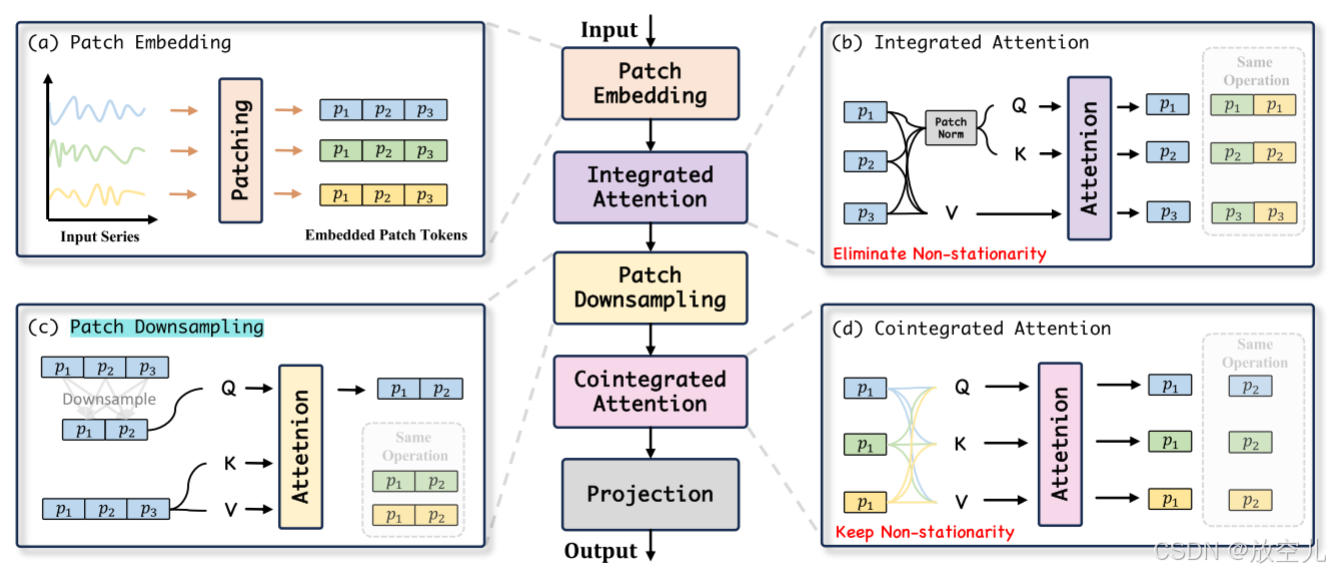
这篇论文提出了一种名为TimeBridge的新框架,旨在解决多变量时间序列预测中非平稳性带来的挑战。非平稳性(如短期波动和长期趋势)可能导致虚假回归或掩盖重要的长期关系。现有方法通常要么完全消除非平稳性,要么完全保留,未能有效区分其对短期和长期建模的不同影响。TimeBridge的核心思想是通过将输入序列分割为小块(patches),分别处理短期和长期依赖关系。
本文借助了deepseek和自己的理解向大家主要介绍的是时间序列领域的不同场景的SOTA模型(涵盖长/短期预测、单/多变量场景),结合最新顶会论文和开源实现,按技术路线分类整理

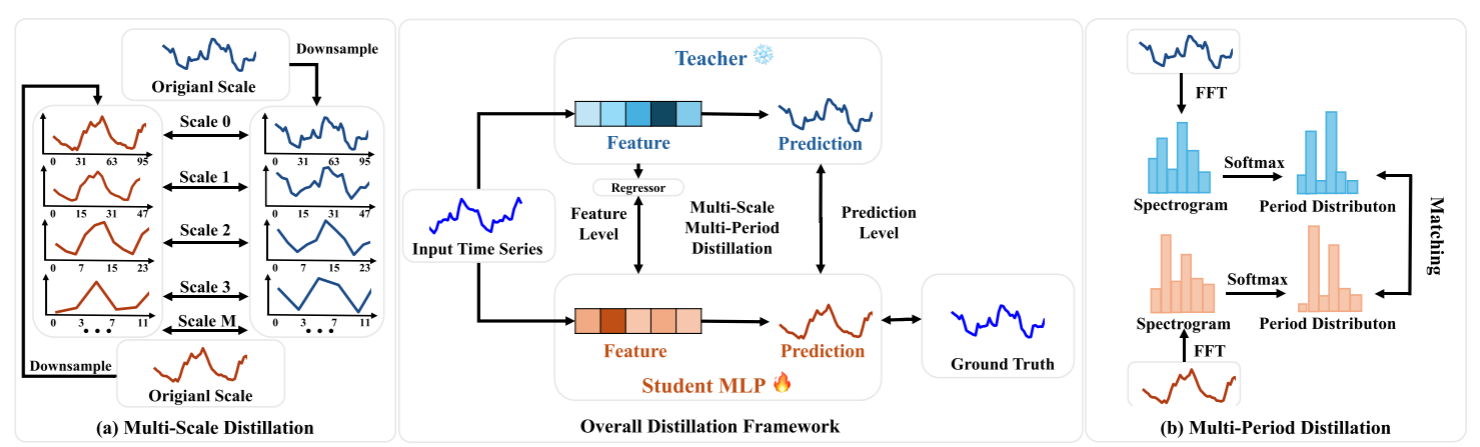
本文提出了一种跨架构知识蒸馏(KD)框架TimeDistill,用于提高轻量级多层感知机(MLP)模型在长期时间序列预测任务上的性能。作者观察到,尽管先进的架构如Transformer和CNN在性能上表现出色,但由于计算和存储需求高,在大规模部署中面临挑战。相比之下,简单的MLP模型具有更高的效率,但性能较低。TimeDistill的关键思想是从教师模型(如Transformer、CNN)中提取补
这篇论文提出了一种名为TimeBridge的新框架,旨在解决多变量时间序列预测中非平稳性带来的挑战。非平稳性(如短期波动和长期趋势)可能导致虚假回归或掩盖重要的长期关系。现有方法通常要么完全消除非平稳性,要么完全保留,未能有效区分其对短期和长期建模的不同影响。TimeBridge的核心思想是通过将输入序列分割为小块(patches),分别处理短期和长期依赖关系。
基于Transformer 及 MLP 模型在时间序列分析中迅速崛起并占据主导,卷积在时间序列任务中因性能欠佳而势头渐弱。探讨如何在时间序列分析中更好地利用卷积,使卷积重回该领域。对传统 TCN 进行现代化改进,使其更适用于时间序列任务,提出 ModernTCN,在五个主流时间序列分析任务中达到先进水平,同时保持卷积模型的效率优势,揭示 ModernTCN 具有更大的有效感受野,能更好地发挥卷积在
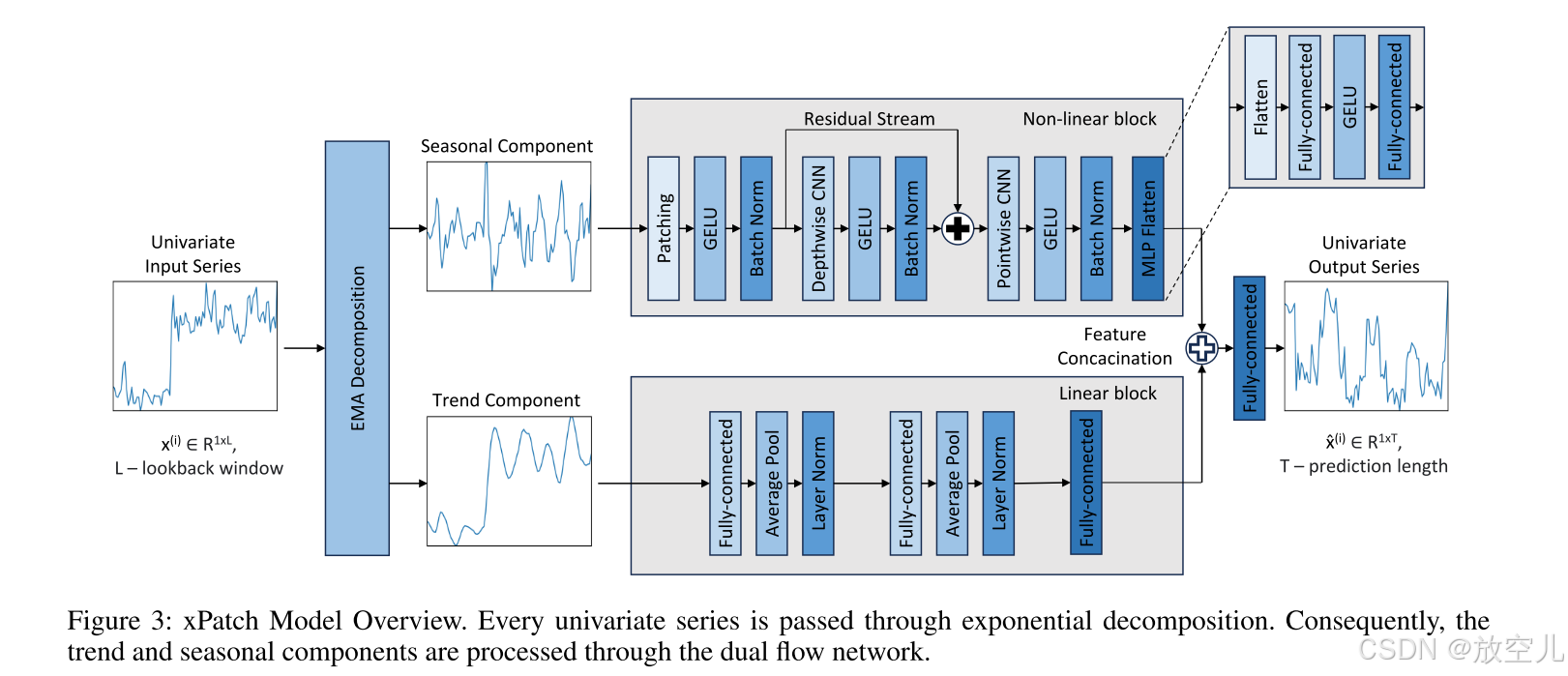
设计了指数补丁(简称 xPatch),这是一种利用指数分解的新型双流架构。受经典指数平滑方法的启发,xPatch 引入了创新的季节趋势指数分解模块。此外,提出了一种由基于 MLP 的线性流和基于 CNN 的非线性流组成的双流架构。该模型研究了在非 Transformer 模型中使用补丁和通道独立性技术的好处。最后,开发了一个稳健的反正切损失函数和一个 S 型学习率调整方案,以防止过拟合并提高预测性
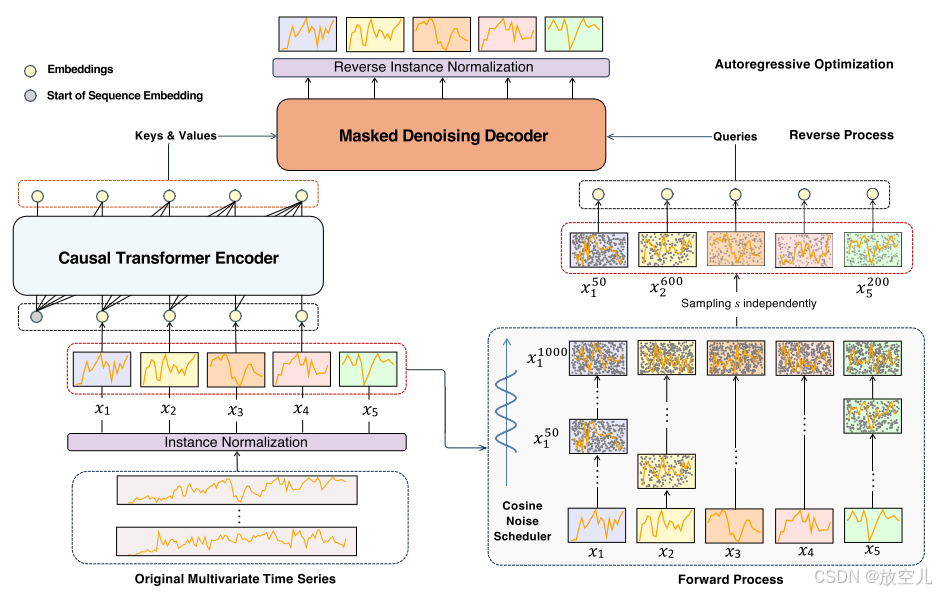
本文提出了TimeDART 一种结合因果Transformer编码器和扩散模型的框架,通过自回归生成和扩散去噪联合优化,同时建模时间序列的长期动态演化(全局特征)与局部细节模式(局部特征)。