- @m0_56695799
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
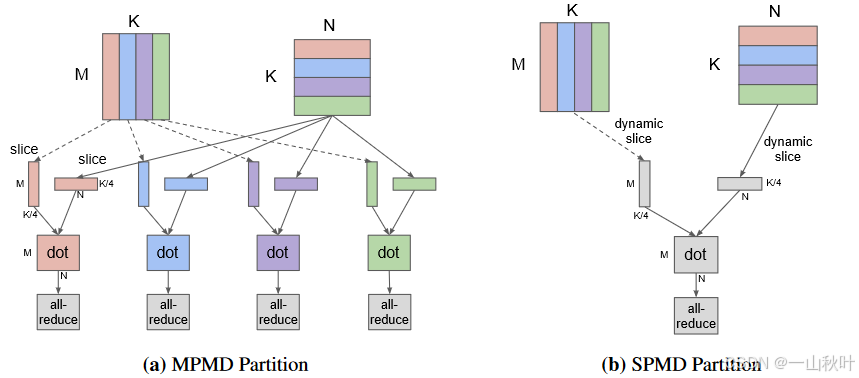
在上一篇博客中,着重于其中的MoE的相关介绍,GShard还有许多其他亮点,像自动并行训练、高效资源利用、弹性扩展等就搬到这里来吧(主要在附录部分)(请在开始本篇之前看看上篇)(写的有点零碎,俺菜鸡能力差点,还有一点小原因可能是实验部分多少有点)(越写越没有信心让大家看了😳)。别看他吹的神乎其神,说不定实际上就那样呢~(网络酸民口气.jpg)的神通众所周知,的计算能力是其必备需求,底层硬件在不断
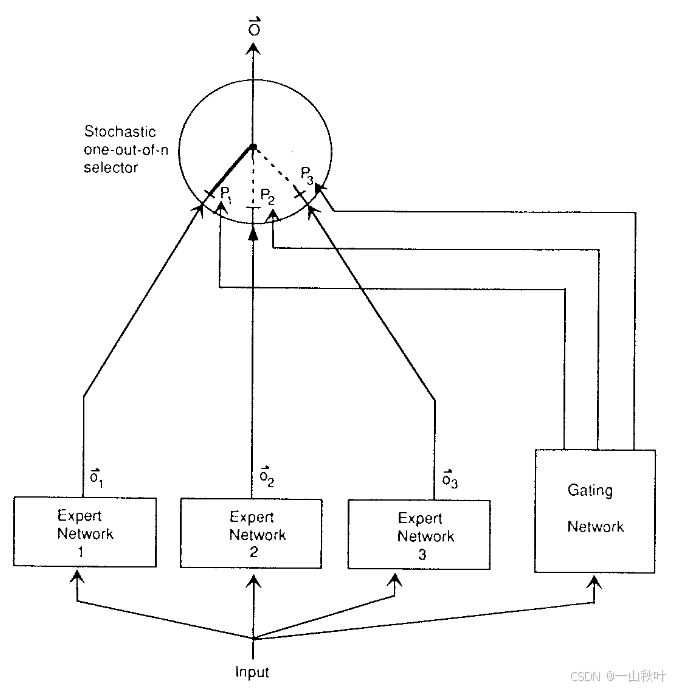
1991年,Geoffrey Hinton和Michael I. Jordan发表的论文被认为是MoE的奠基之作。通过引入专家网络和门控网络的组合,系统能够有效地给不同的专家,从而减少干扰。在论文的实验中希望对说话人的元音音素数据进行识别,那么每个专家可能就专注于区分某一对元音(例如[a]和[A])。2017年,Google发布《型神经网络:稀疏门控的MoE层》(后文简称为“2017年论文”)。通
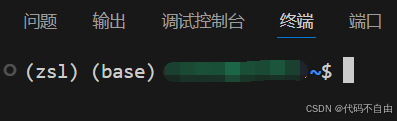
看着好膈应,虽然可以conda deactivate一次去掉(zsl),再conda deactivate一次去掉(base),但每次打开有两括号就很烦。原因在于每次“傻扣”会自动激活一次base环境,只需终端运行一次。这样每次新开一个终端就只显示上次的conda环境啦~
再ssh到新服务器上,你ls是显示不出任何.vscode-server之类的东西的,因为“.”开头的是隐藏文件(夹),得用加个“-a”来显示包含隐藏文件的所有文件。PS:你当然可以找你的好兄弟给你一份他的.vscode-server.zip,但得保证他的vscode版本号和你的一样,打开vscode,点击帮助-》关于即可查看版本号啦!找一个你这破vscode的远程资源管理器能连上的服务器,找到下面
本文介绍了开源视频生成模型万象的技术架构。该模型采用时空变分自编码器(VAE)结构,通过大规模预训练策略实现性能提升。文章重点解析了DiT模型的前向过程,包括输入处理、注意力机制和序列并行等关键模块。模型支持图生视频、指令编辑等任务,接受中文输入,1.3B版本仅需8.19GB显存。详细阐述了文本编码、图像编码、位置编码等输入处理流程,以及基于Triton的高效旋转位置编码实现。同时介绍了针对不同G

在JVP的架构挑战下(比如BF16精度的数值误差,flash attention、上下文并行的复杂实现),在评估指标缺失的情况下(FID用来评估弱条件的imagenet基准还行,但T2I T2V这些强条件任务更强调一些细节属性,比如文本对齐度),如何将连续时间一致性蒸馏(sCM)应用到企业级图像和视频模型?实现兼容并行策略(FSDP、CP)的FlashAttention-2 JVP核,将sCM扩展

在原始叙事中,设置,其中\控制着噪声的增长速度,原始设置中被定义为一个线性调度,还采用线性时间调度。令,定义积分,可以推导出表格中的调度函数,有。通过噪声网络近似分数函数,其中M=1000,对应扰动核的标准差,替换成用原始样本表示的形式,代入s(t),用去噪器表示左边,有,转换一下,得到损失函数为,即实验时采用CIFAR-10对应的“DDPM++ cont. (VP)”权重,含62M可训练参数,噪

再ssh到新服务器上,你ls是显示不出任何.vscode-server之类的东西的,因为“.”开头的是隐藏文件(夹),得用加个“-a”来显示包含隐藏文件的所有文件。PS:你当然可以找你的好兄弟给你一份他的.vscode-server.zip,但得保证他的vscode版本号和你的一样,打开vscode,点击帮助-》关于即可查看版本号啦!找一个你这破vscode的远程资源管理器能连上的服务器,找到下面
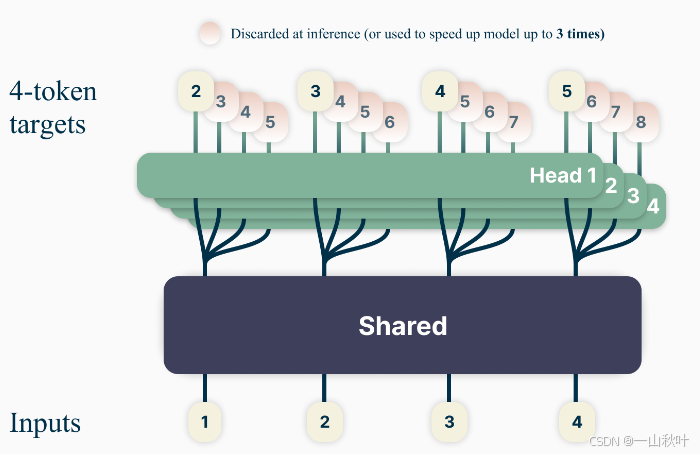
这是一篇发表在24年ICML上的一篇论文,乍一看和博客里的那篇好像,当时讨论到怎么训练并行预测token的几个transformer头的时候,认为将每个头的交叉熵损失的均值作为整体损失的话,内存开销太大,改为每个批量就随机选一个子损失,企图从长期看这种估计无偏,这篇论文似乎直面并解决了这个内存开销的问题。在训练语料的一个位置,模型一次性预测未来n个token,学习目标为努力最小化交叉熵损失方便起见
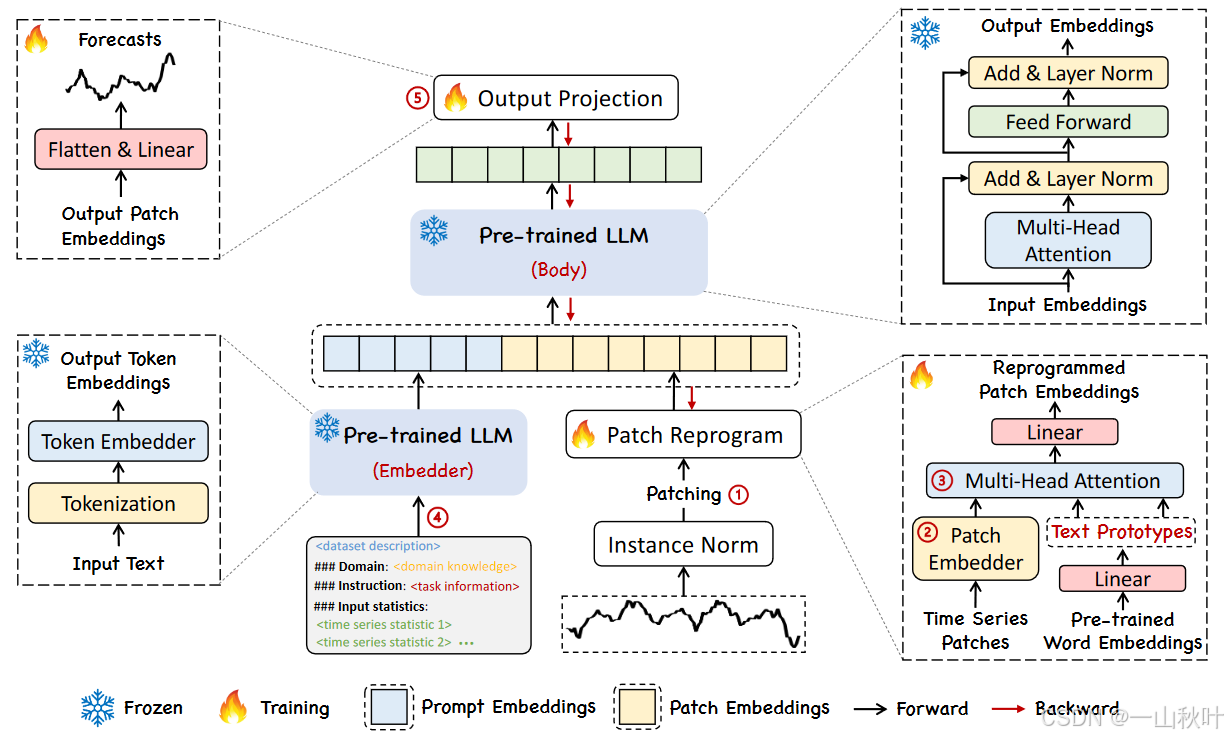
Time-LLM:通过重编译大语言模型进行时序预测》,这是一篇24年发表在ICLR上的论文。针对NLP、CV领域的任务,往往一个大模型就能解决各种问题,而时序预测领域的模型却要针对不同任务和应用进行不同的设计。研究表明LLM在复杂的token序列上有强大的模式识别和推理能力,但该,以利用这些能力呢?在这篇工作中推出了一个重编译框架Time-LLM,在保持主体的语言模型不变的情况下,将LLM应用到时