- @m0_56602092
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
修改.bashrc文件vim ~/.bashrc然后在最后加入下面两行代码export LANG=en_US:UTF-8export LANGUAGE=en_US:en关闭文件后,最后再执行下面代码source ~/.bashrc
上:机器学习笔记(3)——梯度下降算法一、多变量线性回归及其预测函数和代价函数的定义目前为止,我们探讨了单变量的回归模型,现在我们对房价模型增加更多的特征,例如房间数、楼层等,构成一个含有多个变量的模型,探讨多变量线性回归问题。如下表所示,其中x(i):表示第i个样本的各个特征的值组成的向量。x(i)j:表示第i个样本中第j个特征的值预测函数:那么这样多变量的模型的预测函数就和之前单变量的不一样了
如上文所说,面对高维度、更多参数的情况时,通过画图来寻找最小代价函数值是不现实的,因此本文介绍一种可以将代价函数J最小化的算法——梯度下降(Gradient Descent)。梯度下降是很常用的算法,不仅被用在线性回归上,还被广泛应用于机器学习的众多领域。直观理解梯度下降以包含两个参数的如下代价函数J为例,首先任选一个参数点作为起始点,然后我们需要一点一点的改变(微分)这两个参数的大小,并且每一次
一、推荐系统(Recommender Systems)推荐系统是机器学习中的一个重要应用,有很多的网站都会通过推荐系统来推荐新产品给用户,如亚马逊推荐新书给你,网飞公司试图推荐新电影给你,这些推荐系统是根据浏览你过去买过什么书或评价过什么电影来判断。这些系统会为亚马逊和像网飞这样的公司带来很大一部分收入,因此,对推荐系统性能的改善,将对这些企业的有实质性和直接的影响。我们首先来通过一个电影推荐例子
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。如下线性回归问题的预测函数,第一个欠拟合,而第三个就是过拟合了过拟合:可以非常好的适配训练用的数据,但是对于新数据的预测效果很差。又称这个算法具有高方差,就是为了适配现有的数据用了过多的
上:机器学习笔记(3)——梯度下降算法一、多变量线性回归及其预测函数和代价函数的定义目前为止,我们探讨了单变量的回归模型,现在我们对房价模型增加更多的特征,例如房间数、楼层等,构成一个含有多个变量的模型,探讨多变量线性回归问题。如下表所示,其中x(i):表示第i个样本的各个特征的值组成的向量。x(i)j:表示第i个样本中第j个特征的值预测函数:那么这样多变量的模型的预测函数就和之前单变量的不一样了
一、问题场景在idea中运行程序时报错:错误: 找不到或无法加载主类并且在程序的main方法左侧没有像往常一样有三角形的运行标识符二、原因分析打开右上角的Edit Configurations,发现有飘红报错,说找不到这个类所在的包再打开左侧的工程文件目录,发现上述包所在的目录是一个普通目录,导致编译器找不到这个路径三、解决方案右击包所在的目录scala,选择Mark Directory as -
## 一、问题场景在idea中配置了Go编程环境,可以运行Go程序,但是无法debug,报错error layer=debugger could not patch runtime.mallogc: no type entry found, use 'types' for a list of valid types## 二、解决方案这是由于idea中使用的dlv.exe版本太老导致,直接在终端中执

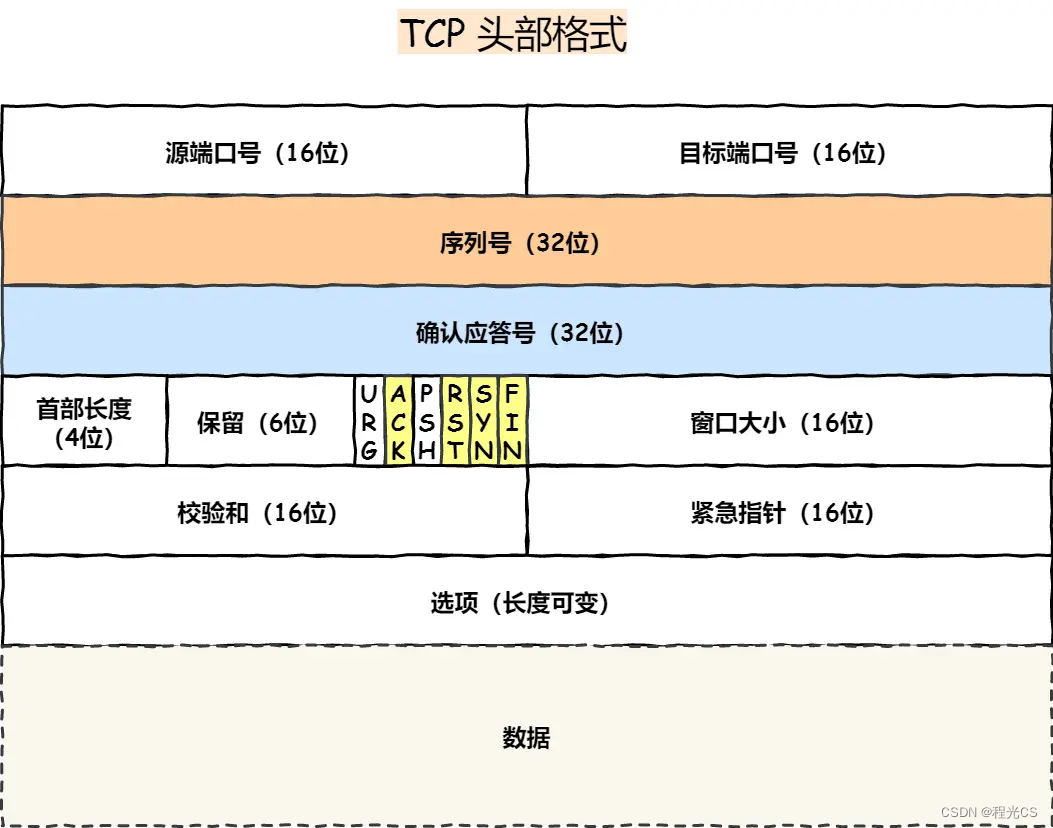
一、建立TCP连接 —— 三次握手(1)客户端向服务端发送一个携带客户端随机初始序列号x的SYN报文,进入SYN-send状态。(2)服务端收到后将其加入到半连接队列,进入SYN-rcvd状态。然后向客户端回复携带服务端初始序列号y的SYN+ACK报文,这里的ack确认应答号就是x+1。(3)客户端收到后再向服务端发送一个确认应答号为y+1的ACK包,服务端收到后确认建立连接,放入到全连接队列,此
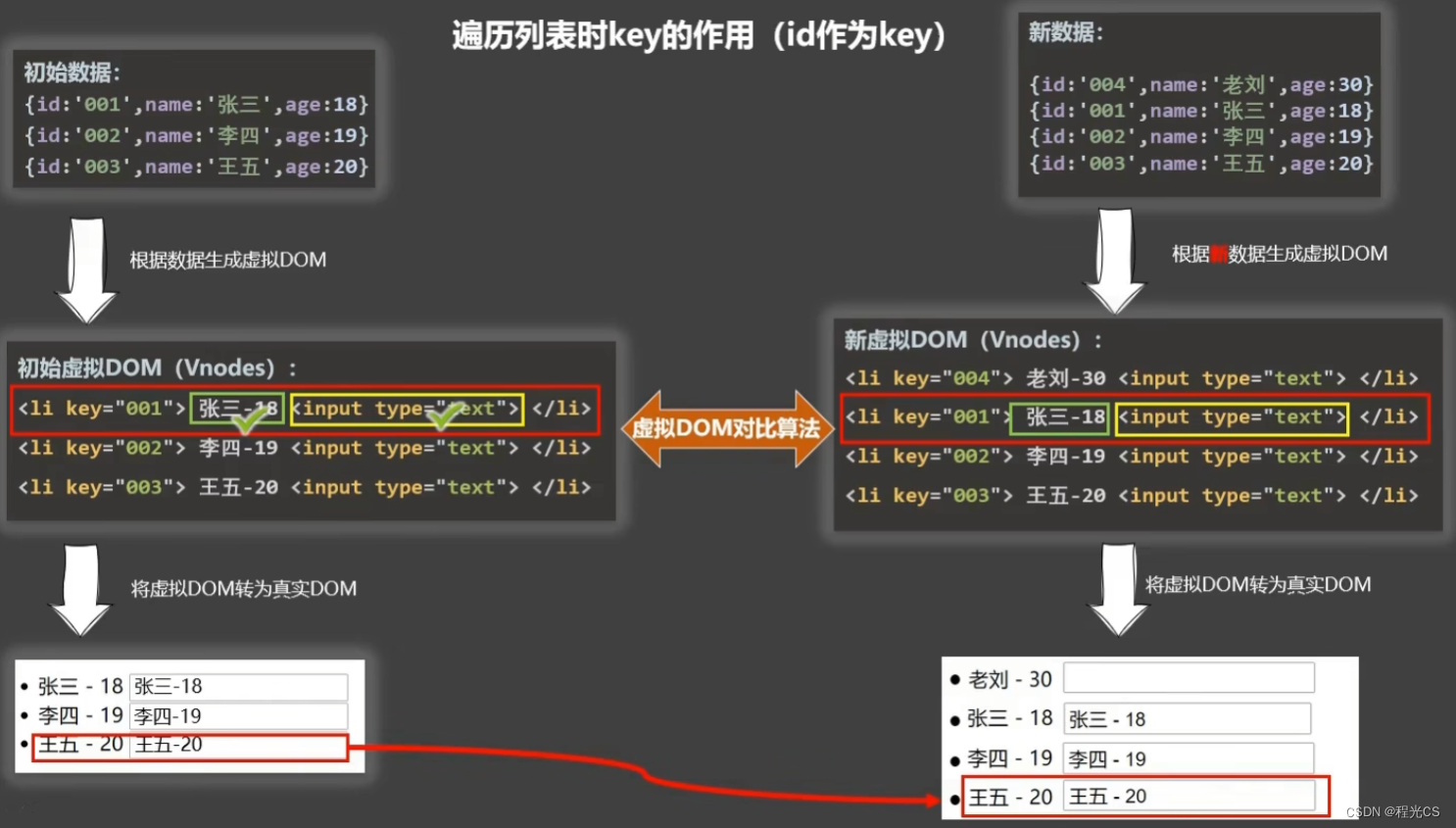
页面中列表重新渲染时,为实现页面元素的复用,在vue中有一个虚拟DOM对比算法,key相同的项中相同的元素会直接复用而不会重新渲染,因此,如果使用根据数组索引index自动编号的key,在添加或移除列表项时由于列表项索引的变化可能会造成复用了其它列表项中的元素,从而造成数据错乱。当同时条件渲染多个元素时,可以将v-if与template的配合使用,若条件值为false,vue模板解析时会直接去掉这