




- @m0_56341622
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。简单理解:可以把监督学习理解为我们教机器如何做事情。定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据

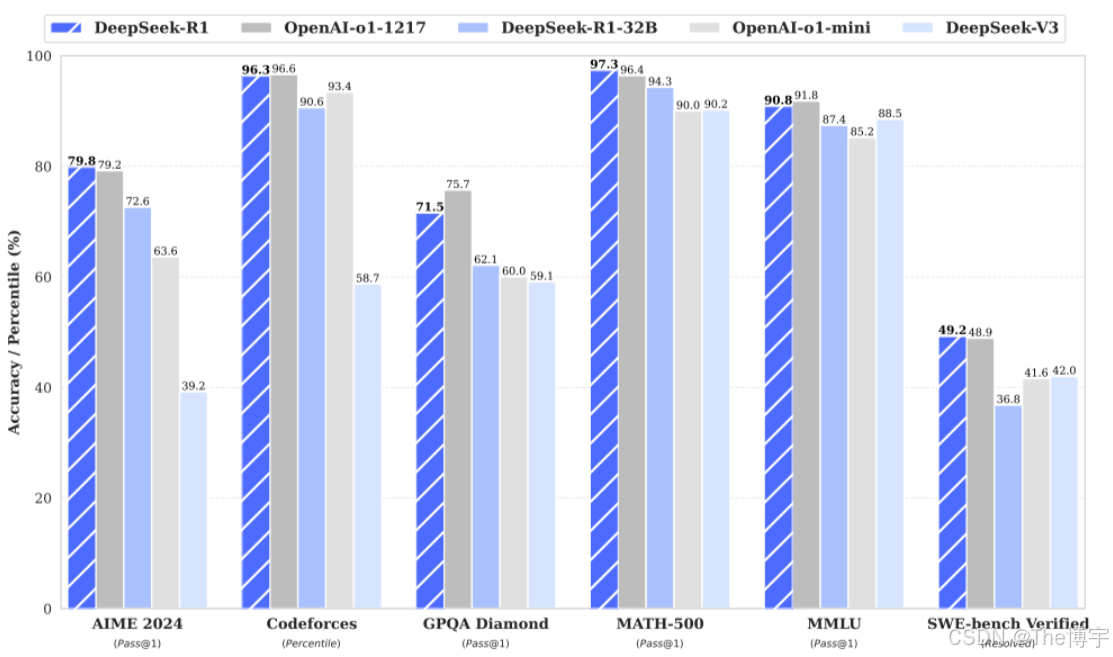
近年来,大语言模型(LLMs)正在经历快速的迭代和进化,并正在逼近通用人工智能(AGI)。最近,后训练已成为完整训练流程中的一个重要组成部分。研究表明,它可以提高推理任务的准确 性,与社会价值观保持对齐,并适应用户偏好,同时相较于预训练所需的计算资源相对较少。在推理能 力方面,OpenAI 的 o1 系列模型通过增加思维链推理过程的长度,首次引入了推理时扩展的方法。这种 方法在数学、编程和科学推理
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。简单理解:可以把监督学习理解为我们教机器如何做事情。定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据
近年来,大语言模型(LLMs)正在经历快速的迭代和进化,并正在逼近通用人工智能(AGI)。最近,后训练已成为完整训练流程中的一个重要组成部分。研究表明,它可以提高推理任务的准确 性,与社会价值观保持对齐,并适应用户偏好,同时相较于预训练所需的计算资源相对较少。在推理能 力方面,OpenAI 的 o1 系列模型通过增加思维链推理过程的长度,首次引入了推理时扩展的方法。这种 方法在数学、编程和科学推理