
写文章




- @m0_55995964
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
20260113论文阅读记录《强化学习:GDPO》和《视频推理:VideoAuto-R1》
目前的流行算法(GRPO)在处理“既要答案对、又要格式好”这种多目标训练时,因为把分算混了(归一化问题)导致效果不好;这篇论文提出的GDPO通过分开算分再组合(解耦归一化),成功解决了这个问题,让模型训练得更好、更稳定。思维链(Chain-of-Thought, CoT)推理已成为多模态大语言模型在视频理解任务中的一项有力工具。然而,其相对于直接作答的必要性与优势尚未得到充分探讨。
nougat配置教程记录,最快方法与解决报错问题
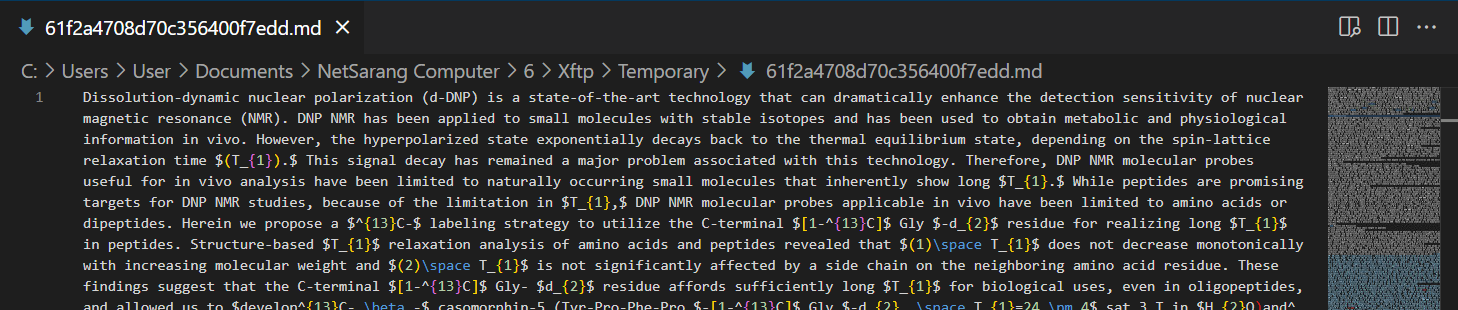
记录nougat配置过程以及解决各种问题。
在虚拟桌面安装vscode插件,vscode-markdown-preview-enhanced
能渲染markdown的vscode插件-vscode-markdown-preview-enhanced安装。
到底了