




- @m0_37586991
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在强化学习 (RL) 中,仅仅知道“你得了多少分”通常是不够的。单纯追求高分可能会导致各种副作用,例如过度探索、模型不稳定,甚至偏离合理策略的“捷径”行为。为了应对这些挑战,RL 采用了多种机制,例如Ctritic(价值函数)、Clip操作、Reference模型以及较新的组相对策略优化 (GRPO)。为了使这些概念更加直观,我们打个比方:将强化学习的训练过程想象成小学考试场景。我们(正在训练的模
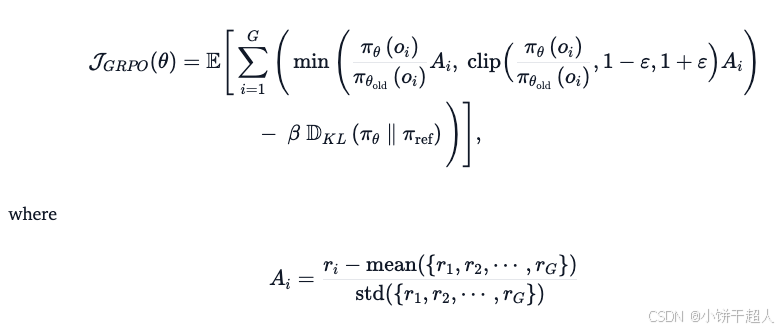
预测值与真实值的皮尔逊相关系数,衡量线性相关性,范围[-1, 1],绝对值越接近1越好。:对称平均绝对百分比误差,通过对称分母解决MAPE的不对称问题。:预测误差相对于基线模型(用均值预测)的比例,值越小越好。:预测误差的百分比平方平均,进一步放大相对大误差的影响。:MSE的平方根,恢复原始数据单位,平衡大误差的影响。:预测误差的平均绝对值,直观反映预测偏差的大小。:预测误差的百分比平均,直观反映
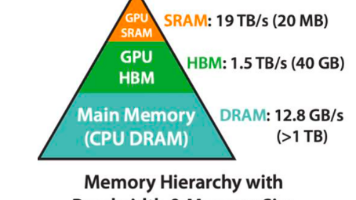
类型核心结构速度容量(同面积)成本(单位容量)典型应用SRAM触发器(6晶体管)最快(ns级)最小最高CPU缓存(L1/L2/L3)HBM3D堆叠DRAM快(高带宽)较大中高高端GPU、AI芯片DRAM电容+晶体管中等大低计算机内存、显卡显存简单来说,SRAM是“高速小容量”的缓存,DRAM是“中速大容量”的主存,HBM则是“超高带宽、高密度”的高端存储方案,三者分别满足了不同场景对速度、容量和成
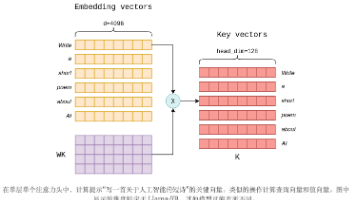
在大语言模型推理过程中,KV Cache(Key-Value Cache)是一个关键优化技术,它缓存了之前计算的键值对,避免重复计算。PagedAttention借鉴了操作系统中虚拟内存的页面管理思想,将KV Cache分割成固定大小的页面(pages),每个页面存储固定数量的token的KV对。
大型语言模型 (LLM) 的卓越功能也带来了巨大的计算挑战,尤其是在 GPU 内存使用方面。这些挑战的根源之一在于所谓的键值 (KV) 缓存,这是 LLM 中采用的一项关键优化技术,用于确保高效的逐个标记生成。此缓存会消耗大量 GPU 内存,以至于它本身会限制 LLM 的性能和上下文大小。本文介绍了键值缓存优化技术。首先,本文将解释键值缓存的基本工作原理,然后深入探讨开源模型和框架实现的各种方法,
在强化学习 (RL) 中,仅仅知道“你得了多少分”通常是不够的。单纯追求高分可能会导致各种副作用,例如过度探索、模型不稳定,甚至偏离合理策略的“捷径”行为。为了应对这些挑战,RL 采用了多种机制,例如Ctritic(价值函数)、Clip操作、Reference模型以及较新的组相对策略优化 (GRPO)。为了使这些概念更加直观,我们打个比方:将强化学习的训练过程想象成小学考试场景。我们(正在训练的模
在强化学习 (RL) 中,仅仅知道“你得了多少分”通常是不够的。单纯追求高分可能会导致各种副作用,例如过度探索、模型不稳定,甚至偏离合理策略的“捷径”行为。为了应对这些挑战,RL 采用了多种机制,例如Ctritic(价值函数)、Clip操作、Reference模型以及较新的组相对策略优化 (GRPO)。为了使这些概念更加直观,我们打个比方:将强化学习的训练过程想象成小学考试场景。我们(正在训练的模
推测性采样算法通过小模型快速生成草稿序列,再经大模型并行验证与修正,在不改变目标模型分布的前提下实现2-2.5倍加速。该算法分为三阶段:草稿生成阶段由小模型自回归生成K个候选token;并行评分阶段由大模型一次性计算K+1个上下文的概率分布;验证修正阶段通过概率比较和随机采样决定是否保留或修正草稿token。算法关键创新在于通过并行计算减少大模型调用次数,同时利用数学设计确保生成质量与单独使用大模
类型核心结构速度容量(同面积)成本(单位容量)典型应用SRAM触发器(6晶体管)最快(ns级)最小最高CPU缓存(L1/L2/L3)HBM3D堆叠DRAM快(高带宽)较大中高高端GPU、AI芯片DRAM电容+晶体管中等大低计算机内存、显卡显存简单来说,SRAM是“高速小容量”的缓存,DRAM是“中速大容量”的主存,HBM则是“超高带宽、高密度”的高端存储方案,三者分别满足了不同场景对速度、容量和成
问题首先安装 jupyter,命令为pip install jupyter(venv) D:\MLiA>pip install jupyterCollecting jupyterDownloading https://files.pythonhosted.org/packages/83/df/0f5dd132200728a86190397e1ea87cd76244e42...