- @lzzyok
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1、时间的重要性,弄明白为什么需要有序?当iot设备上传的轨迹数据是乱序时,那业务在处理时就会有误,如计算超速就不准确。在直播带货中,每小时计算销售金额,并给主播按时结算报酬,如果时间乱了,把19:00的算到20:00了,那就是问题了。对于流计算中的乱序,应该怎么排序呢?在flink中,流计算的数据是事件,每个事件都会有自己的产生时间(如:每个gps点都会有自己的时间),所以流计算中的排序是按时间
mysql根据中文条件查询时,报如标题的异常,其本质是:数据库出现了两种字符集。SHOW VARIABLES LIKE 'character_set_%';+--------------------------+----------------------------+| Variable_name | Value |+--------------------------+------------
问题:今天在测试环境发现,各服务能收到canal的通知,但是没有影响的数据内容。开始以为是应用程序问题,排查后发现有多个应该都是这个情况。所以怀疑是canal问题。先说一下系统的实现情况:mysql---(binlog)--->canal------>canal消费端---->kafka----->应用程序消费数据处理步骤:1、查询canal的日志(canal有两个日志,一
人事信息管理系统中,需要管理用户的个人身份照片。通常这种格式的照片只有几 K 到几十 K 大小,保存在数据库中易于进行管理和维护(如果放在文件夹下容易发生误操作而引起数据被修改或丢失)。 功能设计: 给用户提供一个上传的界面,并设定上传文件的尺寸上限。用户上传的照片先统一保存在一个临时文件夹中,之后可以用指向临时文件夹中的这个图片,让用户可以预览自己上传的照片。当所有的用户信息都收集完
1、前提项目中使用了spring-kafka1.3版本,也用了2.5版本。但是对于offset的提交时机是模糊的,这次通过源码分析和资料进一步明确。2、认识KafkaConsumer的偏移量KafkaConsumer是kafka客户端一个入口,通过KafkaConsumer可以拉取kafka服务上的数据、发送心跳包、上报消费分区的偏移量(offset)。为了保证调用KafkaConsumer.po
phoenix中的命名空间可以类似于Mysql中的库名。默认情况下,所创建的表都是在默认的命名空间中。1、启用名称空间映射参数1)phoenix.schema.isNamespaceMappingEnabled:默认false,如果启用了它,那么使用模式创建的表将映射到名称空间。这需要在客户端和服务器端同时设置。如果设置一次,则不应回滚。启用此属性后,旧客户端将无法工作。2)phoenix.sch
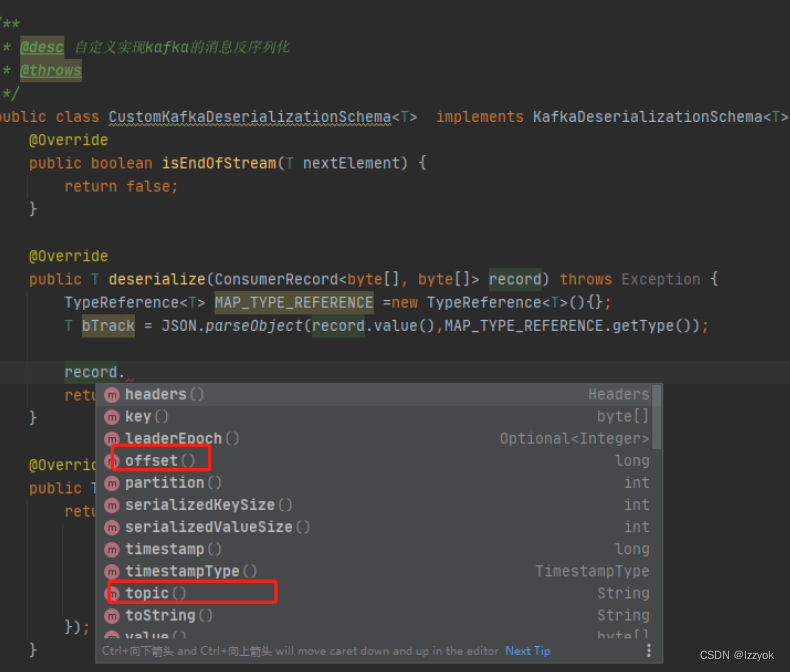
实现KafkaDeserializationSchema解决Flink中对kafka消息反序列化问题