- @lsfeitianzhuzhuxia
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MulDE: Multi-teacher Knowledge Distillation for Low-dimensional Knowledge Graph EmbeddingsKnowledge Transfer via Dense Cross-Layer Mutual-DistillationDistilling a Powerful Student Model via Online Kno
ECCV2022 | 多模态融合检测新范式!基于概率集成实现多模态目标检测github代码

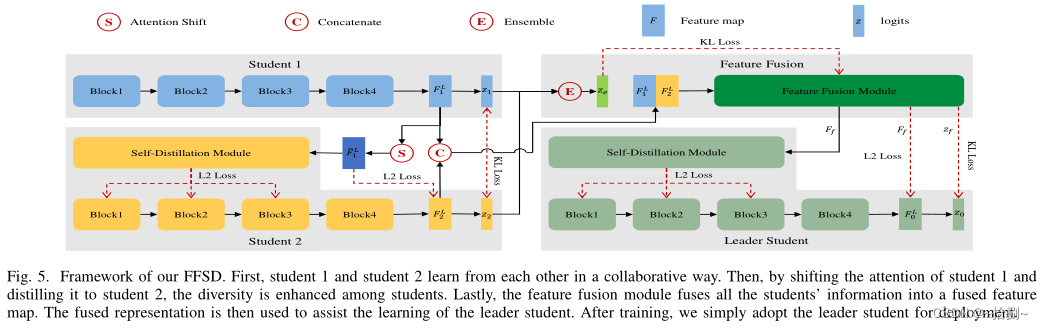
这项工作通过协作学习提出了一种高效而有效的在线知识提取方法,称为KDCL,它能够持续提高具有不同学习能力的深度神经网络(DNN)的泛化能力。与现有的两阶段知识提取方法不同,即预先训练一个具有大容量的DNN作为“教师”,然后将教师的知识单向(即单向)转移到另一个“学生”DNN,KDCL将所有DNN视为“学生”,并在单个阶段对其进行协作训练(在协作训练期间,知识在任意学生之间转移),实现并行计算、快速

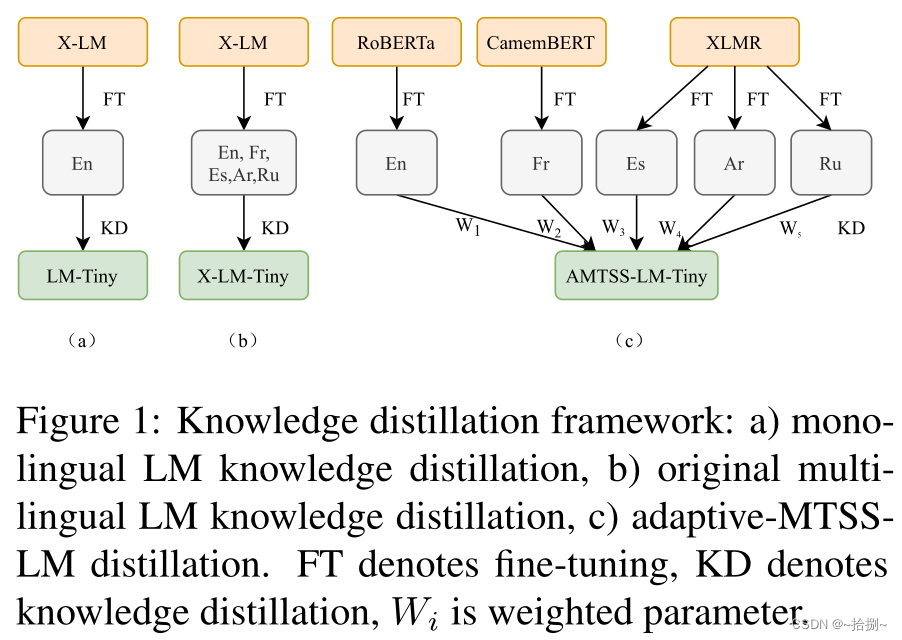
AMTSS: An Adaptive Multi-Teacher Single-Student Knowledge Distillation Framework For Multilingual Language InferenceLearning Accurate, Speedy, Lightweight CNNs via Instance-Specific Multi-Teacher
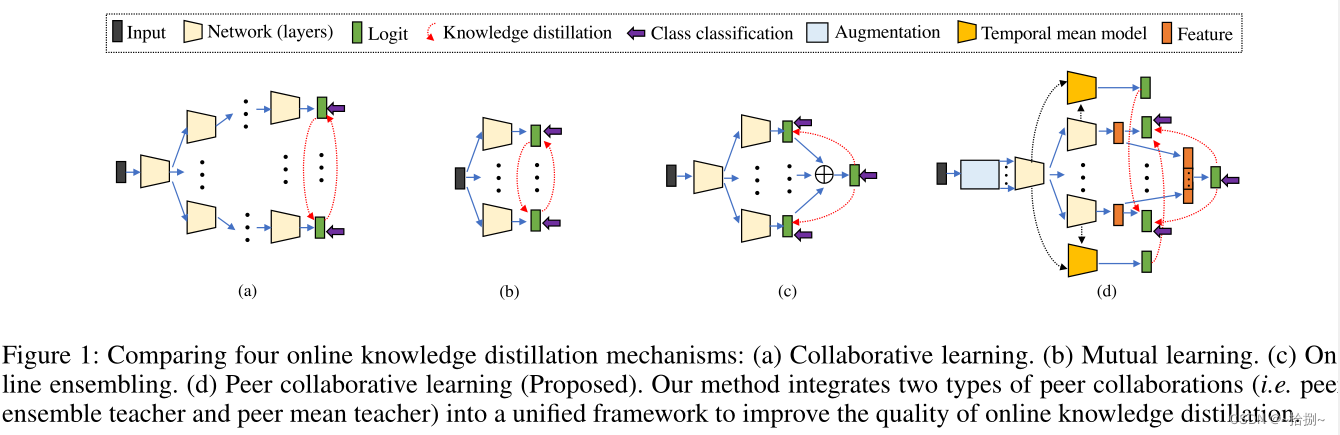
传统的知识蒸馏使用两阶段训练策略将知识从高容量教师模型转移到紧凑的学生模型,这严重依赖于预先训练的教师。最近的在线知识提炼通过协作学习、相互学习和在线集成,遵循一个阶段的端到端培训方式,减轻了这一限制。然而,协作学习和相互学习无法构建在线高容量教师,而在线集成忽略了分支之间的协作,其逻辑总和阻碍了集成教师的进一步优化。在这项工作中,我们提出了一种新的用于在线知识提取的对等协作学习方法,该方法将在线
教师免费在线知识蒸馏(KD)旨在协同训练多个学生模型的集合,并从彼此中提取知识。尽管现有的在线KD方法实现了理想的性能,但它们通常将类概率作为核心知识类型,而忽略了有价值的特征表示信息。我们提出了一个用于在线KD的相互对比学习(MCL)框架。MCL的核心思想是以在线方式在一组网络之间执行对比分布的相互交互和传递。我们的MCL可以聚合跨网络嵌入信息,并最大化两个网络之间相互信息的下界。这使得每个网络
教师免费在线知识蒸馏(KD)旨在协同训练多个学生模型的集合,并从彼此中提取知识。尽管现有的在线KD方法实现了理想的性能,但它们通常将类概率作为核心知识类型,而忽略了有价值的特征表示信息。我们提出了一个用于在线KD的相互对比学习(MCL)框架。MCL的核心思想是以在线方式在一组网络之间执行对比分布的相互交互和传递。我们的MCL可以聚合跨网络嵌入信息,并最大化两个网络之间相互信息的下界。这使得每个网络
1.输入nmtui打开图形化页面2.通过上下键选择,回车Ethernet表示直连,这里我用的是wifi就不设置直连了,设置方式都一样3.选择连接的WiFi,回车上下键移动到IPv4 CONFIGURATION 上,选中Automatic,回车4.选择Manual,移动光标到Show,回车5.移动光标到Add,填写IP地址注意地址要在同一局域网段可以通过在cmd中输出ipconfig获取局域网ip地