- @lizhi888999AI
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 多模态感知是具身智能机器人实现环境交互与自主决策的核心基础,通过融合视觉、触觉、听觉等多元传感信息,突破单一模态的感知局限(如视觉易受干扰、触觉依赖接触),使机器人具备接近人类的综合环境认知能力。视觉负责全局定位与物体识别,触觉支撑精细力控操作,两者互补形成“看得见+摸得准”的闭环。多模态融合技术(数据级、特征级、决策级)在工业装配、家政服务、医疗手术等场景加速落地,但面临触觉传感器成本高

2026具身智能学习与开发指南 2026年是具身智能从实验室迈向产业落地的关键年,人形机器人进入工业产线,VLA模型泛化能力显著提升。本文提供全路径学习资源: 入门筑基:分三阶段学习,涵盖机器人学、多模态AI、控制理论,推荐《机器人学导论》和开源教程。 核心论文:精读奠基性研究(如RT-1/2、OpenX-Embodiment)和2026前沿成果(如Bi-Adapt、DreamDojo)。 工具矩

摘要:深度学习通过多层神经网络模仿人脑机制,实现了端到端的层次化特征学习。主要模型包括:CNN(图像处理)、RNN(序列数据处理)、Transformer(自注意力机制)和GAN(对抗生成)。这些模型在图像识别、自然语言处理等领域取得突破性进展,如AlexNet、GPT等里程碑式成果。深度学习的发展经历了萌芽期、沉淀期和爆发期三个阶段,目前已成为人工智能的核心技术,展现出强大的数据处理和模式识别能
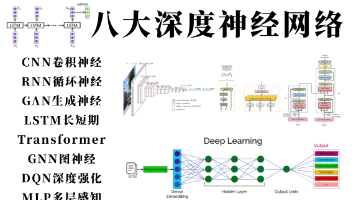
摘要:深度学习通过多层神经网络模仿人脑机制,实现了端到端的层次化特征学习。主要模型包括:CNN(图像处理)、RNN(序列数据处理)、Transformer(自注意力机制)和GAN(对抗生成)。这些模型在图像识别、自然语言处理等领域取得突破性进展,如AlexNet、GPT等里程碑式成果。深度学习的发展经历了萌芽期、沉淀期和爆发期三个阶段,目前已成为人工智能的核心技术,展现出强大的数据处理和模式识别能
2026具身智能学习与开发指南 2026年是具身智能从实验室迈向产业落地的关键年,人形机器人进入工业产线,VLA模型泛化能力显著提升。本文提供全路径学习资源: 入门筑基:分三阶段学习,涵盖机器人学、多模态AI、控制理论,推荐《机器人学导论》和开源教程。 核心论文:精读奠基性研究(如RT-1/2、OpenX-Embodiment)和2026前沿成果(如Bi-Adapt、DreamDojo)。 工具矩
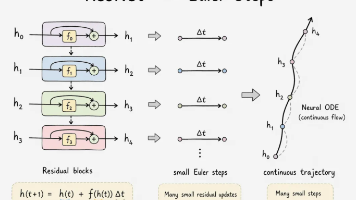
《修真四境:神经网络通向AGI的修炼之路》摘要 本文以修真境界为喻,系统阐述了理解神经网络的四个递进视角:金刚境(偏微分方程数值解法)、指玄境(流形几何展平)、天象境(纤维丛联络)和陆地神仙境(量子测量类比)。每提升一境,都能揭示更深层的结构本质。四境合一指向AGI的必然形态:不是单一巨模型,而是模块化动态系统——小核心处理基础推理,模块化专长区域,个人动态记忆层,统一于张量逻辑基元。关键洞见在于
摘要:深度学习通过多层神经网络模仿人脑机制,实现了端到端的层次化特征学习。主要模型包括:CNN(图像处理)、RNN(序列数据处理)、Transformer(自注意力机制)和GAN(对抗生成)。这些模型在图像识别、自然语言处理等领域取得突破性进展,如AlexNet、GPT等里程碑式成果。深度学习的发展经历了萌芽期、沉淀期和爆发期三个阶段,目前已成为人工智能的核心技术,展现出强大的数据处理和模式识别能
图神经网络(GNN)是一种专门处理图结构数据的深度学习方法,能够有效建模社交网络、分子结构等不规则数据。GNN通过邻居信息聚合更新节点表示,核心公式为h^(l+1)=f(h^l,A)。主要模型包括图卷积网络(GCN)和图注意力网络(GAT),前者通过规范化邻接矩阵实现信息传播,后者引入注意力机制动态调整邻居权重。GNN在社交网络分析、推荐系统和生物信息学等领域展现优势,但面临过平滑、可解释性差等挑

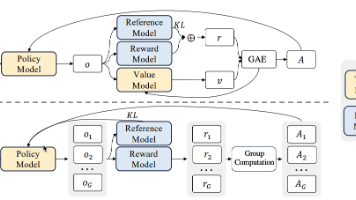
强化学习算法优化路径解析:从PPO到ARPO的技术演进 摘要:本文系统分析了7种主流强化学习优化算法的核心特性与应用场景。PPO作为经典算法提供稳定训练,GRPO针对大模型优化显存效率,DPO简化流程适合轻量级应用。进阶算法如GSPO专注长文本优化,DAPO提升工业训练效率,BAPO平衡历史数据利用。新兴的ARPO则专为智能体决策设计,优化关键工具调用步骤。这些算法覆盖了从基础训练到复杂决策的全场
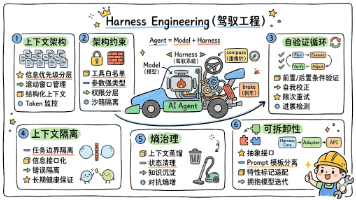
摘要:HarnessEngineering(驾驭工程)是一种提升AIAgent可靠性的工程方法论,其核心是通过优化围绕模型的系统而非频繁更换模型本身。该体系包含六大支柱:1)上下文架构管理信息输入;2)架构约束通过代码强制执行规则;3)自验证循环防止执行异常;4)上下文隔离避免多Agent协作污染;5)熵治理对抗系统复杂性积累;6)可拆卸性实现模块化设计。这些工程机制如同赛车的转向和刹车系统,能确