- @li514006030
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
常用该数据衡量各国或行业的自动化水平、技术进步与产业结构升级,并结合企业或区域层面数据分析机器人普及对生产率、就业、绿色转型与资本结构等经济变量的影响,广泛应用于国际比较、政策评估和数字经济实证研究中。IFR工业机器人数据系统性记录了自20世纪90年代以来全球主要国家和地区在工业机器人领域的年度新增安装量、在役库存、行业分布及应用场景等信息,涵盖汽车、电子、电气、金属加工等多个制造业部门。数据用途

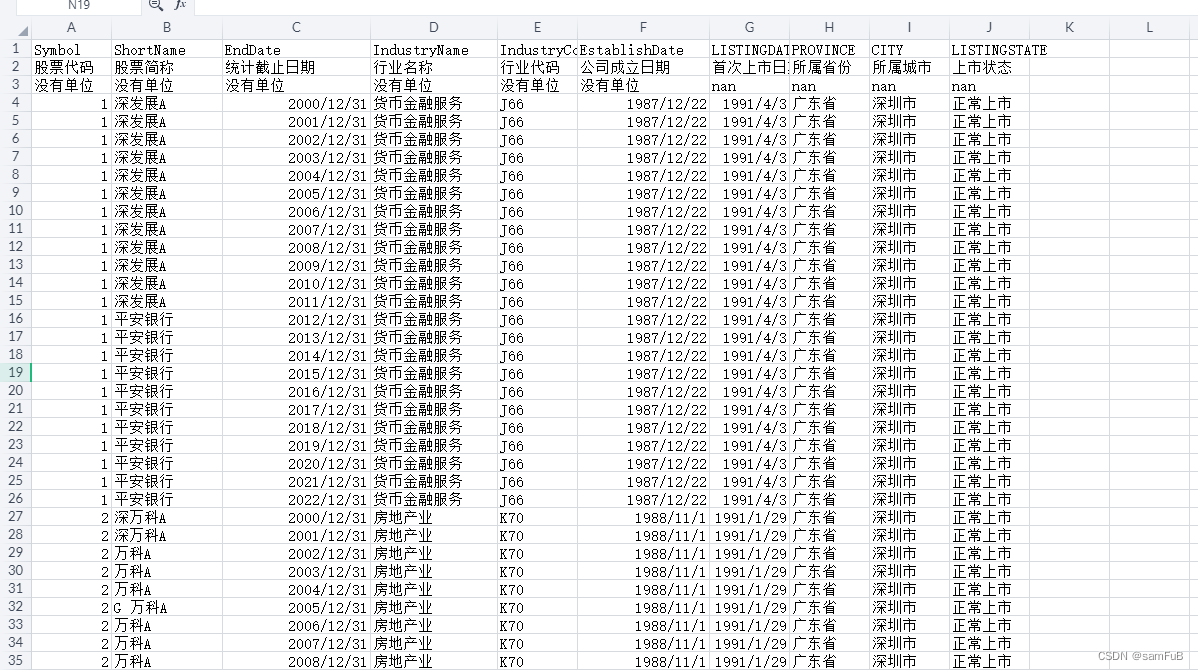
企业行业异质性数据是指不同行业的企业在运营、管理、财务等方面的差异性数据。这些数据可以反映不同行业企业的特点、优势和劣势,以及行业间的异质性对企业经营和投资的影响。通过对企业行业异质性数据的分析,投资者可以更好地了解不同行业企业的特点和投资风险,从而做出更加明智的投资决策。同时,企业也可以通过分析行业异质性数据,了解自身在行业中的地位和优劣势,为自身的战略决策提供依据。股票代码、股票简称、统计截止
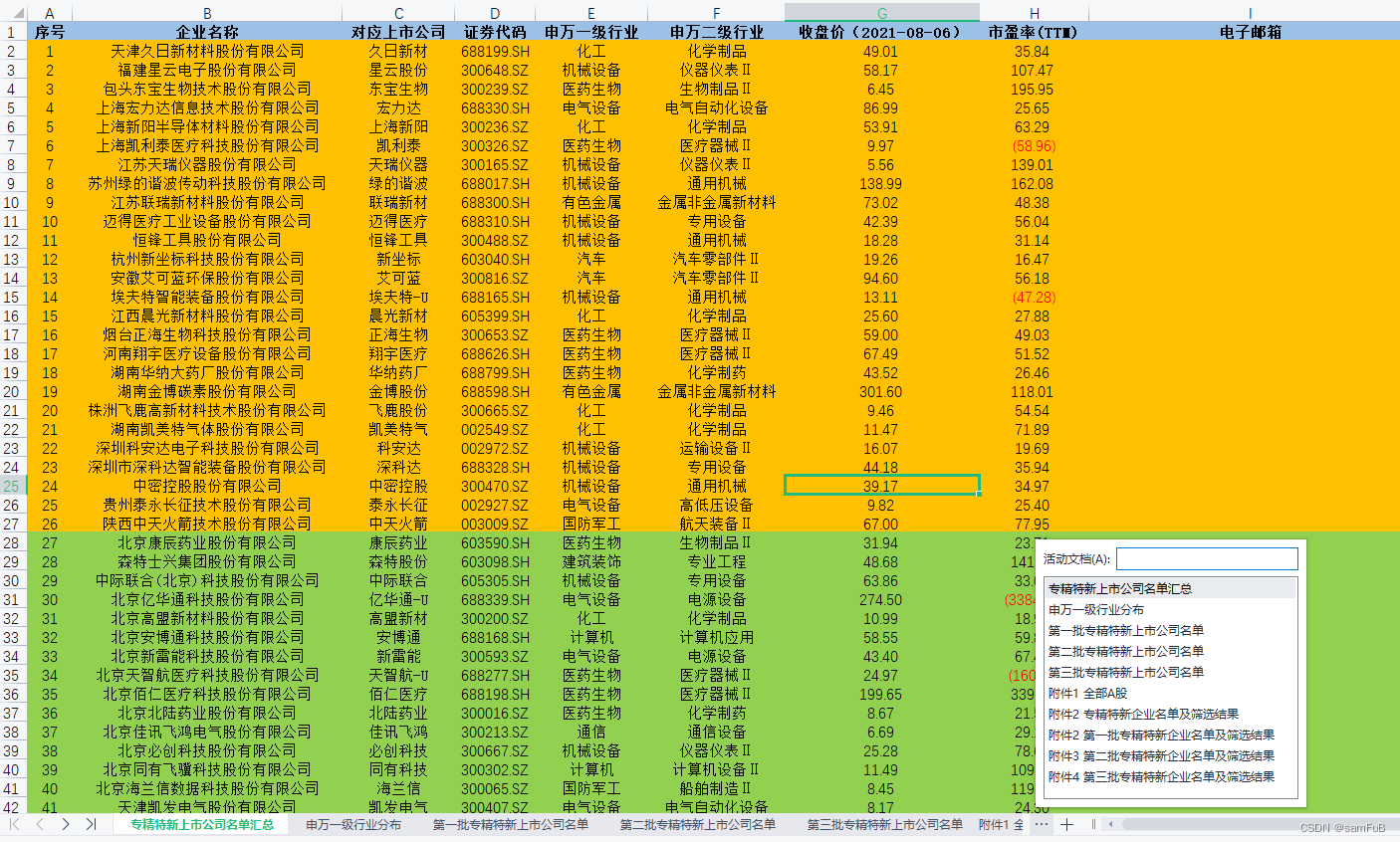
相关介绍:“专新特精”是指专业化、精细化、特色化、新颖化,当下更多代指具备上述特征的中小企业。这一概念最早出现在《中国产业发展和产业政策报告(2011)》中,报告提出,“十二五”时期,要大力推动中小企业向“专精特新”方向发展,即专业、精细管理、特色和创新。2013年,工信部出台相关指导意见,对此进行了深入解读。一、专精特新企业名单汇总1、数据来源:wind2、时间跨度:截止至2021年8月3、区域
2]窦智,韩永辉,王贤彬.关联担保风险管控促进企业创新了吗?——基于担保圈法规的准自然实验[J].财经研究,2023,49(05):49-63.DOI:10.16538/j.cnki.jfe.20221118.203.常用的方法有三种:邹检验(Chow 检验)、似无相关检验 (suest)、费舍尔组合检验(Fisher’s Permutation test)。[1]张德涛,张景静,董帅.环境信息粉

根据王宇等(2020)的研究方法,本文聚焦数字固定资产与数字无形资产核心要素。通过梳理企业年度财务报告中“固定资产明细项目”和“无形资产明细项目”,对相关数据进行筛选与整合。将筛选出的数字固定资产期末金额与数字无形资产期末金额进行加总,进而得出企业数字投资总额。[1]孙忠娟,刘凯月,冯佳林,等.如何实现数字竞争优势:“专精特新”企业数字投资与专业投资的协同逻辑[J].中国工业经济,2025,(04

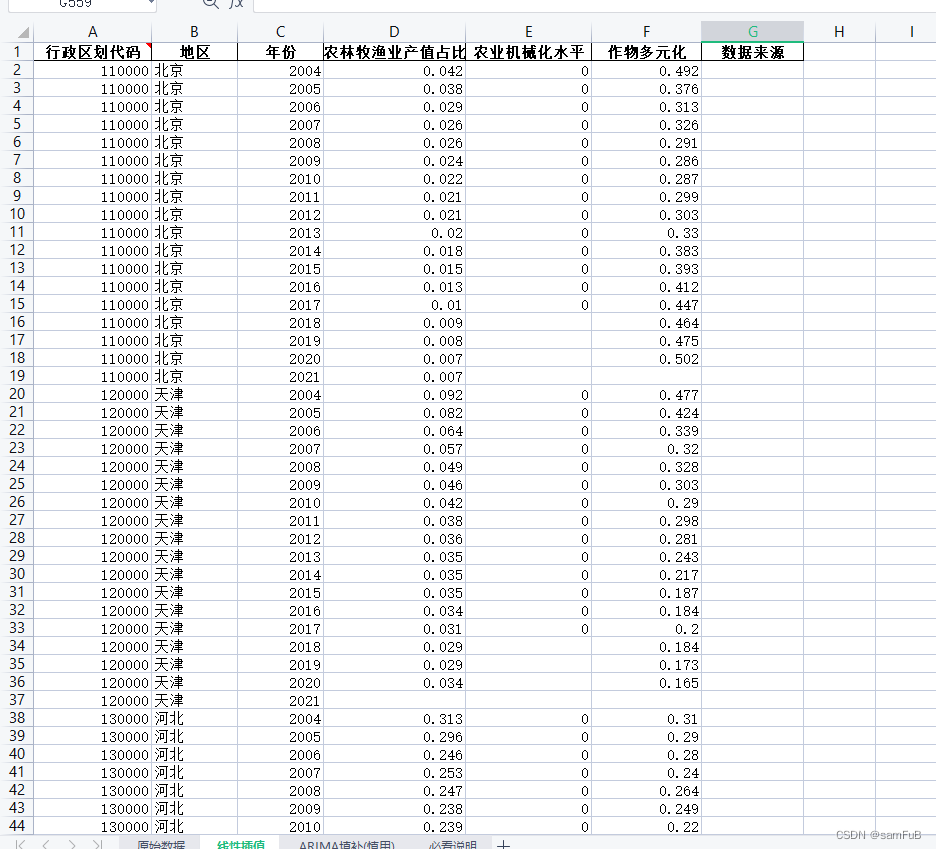
1、数据来源:中国统计年鉴、中国农村统计年鉴2、时间跨度:2004-20213、区域范围:全国所有省份4、指标说明:计算参考文献:[1]徐维祥,李露,周建平,刘程军.乡村振兴与新型城镇化耦合协调的动态演进及其驱动机制[J].自然资源学报,2020,35(9):2044-2062指标体系如下:部分数据如下相关研究:[1]梁琦. 中国工业的区位基尼系数——兼论外商直接投资对制造业集聚的影响[J]. 统
恩格尔系数是指食物支出金额占消费支出总金额的比重,是表示生活水平高低的一个指标。这一概念由19世纪德国统计学家恩格尔提出,他认为,一个家庭收入越少,家庭收入中用来购买食物的支出所占的比例就越大;推而广之,一个国家恩格尔系数越小,这个国家的人民富裕程度越高;数据来源:《中国统计NJ》,《中国城市统计NJ》,《中国农村统计NJ》,《中国社会统计NJ》、各省份的统计公报以及其他统计NJ.行政区划代码、地
1、数据来源:该数据对中国上市公司发明专利的被引用情况进行整理,发明专利引用原始数据主要来自Google Patent,在处理过程中考虑了上市公司及其参控股公司的名称匹配、专利自引用、公司更名等多种情况,由此形成了专利引用基本信息、申请专利的被引用信息、申请专利的被引用数量、授权专利的被引用信息和授权专利的被引用数量五个子数据集。2、时间跨度:1990-2020年3、区域范围:全国4、指标说明:数
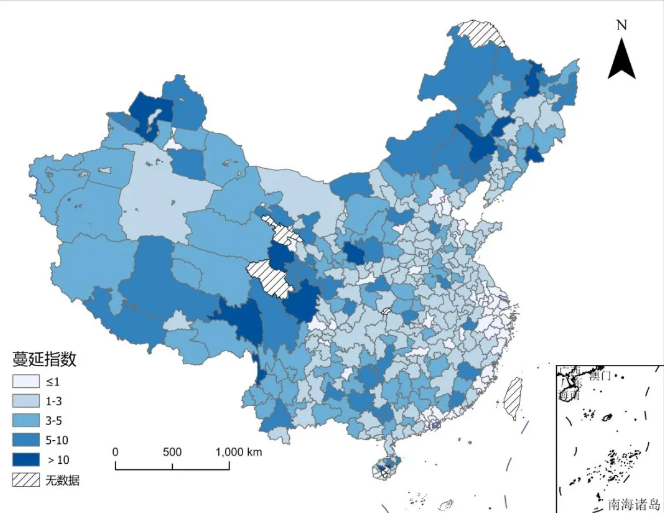
城市蔓延(Urban Sprawl)是指城市无序扩张的现象,其特征包括城市中心区的人口和经济活动向郊区或周边地区扩散,导致城市形态呈现出分散、低密度和区域功能单一的特点。皮皮侠数据团队根据李强的方法依据夜间灯光对我国地级市1990-2023年的城市蔓延程度与城市蔓延指数进行了测算。城市蔓延程度Sprawl = 0.5×(L%- H%)+0.5,其中其中 L% 表示城市内部灯光亮度区域低于全国平均灯
政务微信”指各级政府及其部门在官方微信公众号平台上开设的官方账号,如“xx市人民政府”“xx发布”“xx人社”这些官方公众号,用于发布官方信息、提供公共服务、与群众互动、传播政策等,[3]张科,熊子怡,魏敏.数字政府建设赋能县域外商投资——来自县级政府开通政务微信的证据[J].数量经济技术经济研究,2025,42(09):180-201.[4]张星宇,汤旭东.政务新媒体与城市对高技能创业人才的吸引