




- @lemon_tttea
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
计数排序其实本质上就是一种桶,只不过每个桶对应一个数值,可以理解为桶排序的一种最原始情况,而桶排序是计数排序的升级版,他的桶对应是一个映射区间,而不是一个值,如下图:图片来源:桶排序 而后在桶内完成排序,最后将各个桶连接起来,完成排序。该算法很容易理解,但是其高效与否取决于两个部分,一个是映射空间的划定,最好的情况是n个数组均匀的划分到k个桶中,最坏的情况是输入的数组分配到了同一个桶中;第二
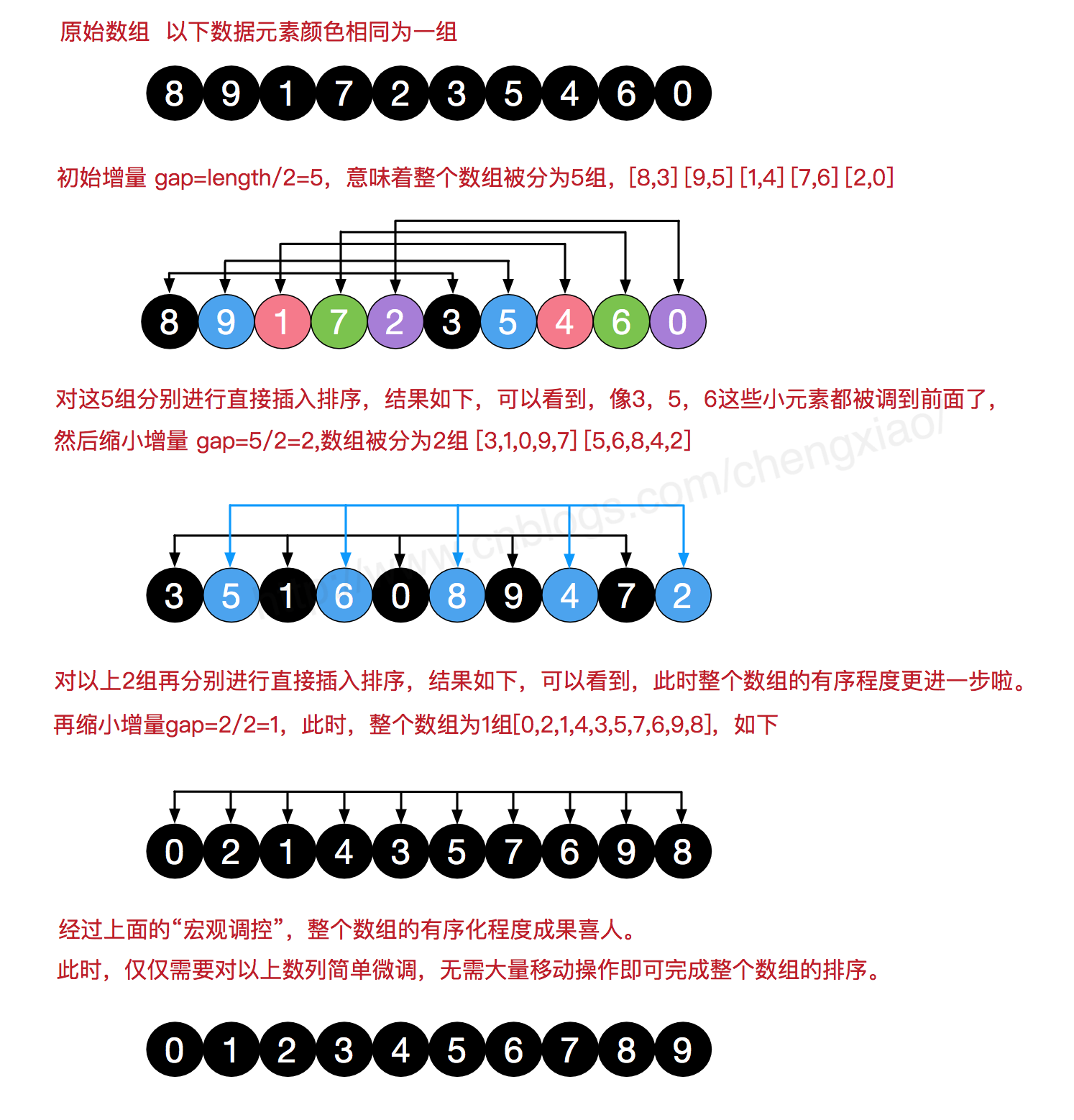
希尔排序也叫递减增量排序,是第一批冲破O(n2)的算法之一,他的算法思想很简单,首先拟定一个增量gap,一般是从len(nums)//3或者len(nums)//2开始,然后对序列nums[i,i+gap,i+gap*k…]进行插入排序,一轮迭代完成后gap=gap//2,知道gao=1是,排序完成。算法步骤是:1:选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk
Rabin-Karp算法总的来说,一句话可以概况,就是一种利用对字符串进行哈希(hash)来解决字符串匹配问题的算法。所以该算法的特点就呼之欲出了,如何对字符串进行hash呢? 这里首先对字符串匹配问题做一个简单的概述。字符串匹配问题可以简单描述成下述形式:Input:一段字符串t,和一个字符串pOutput:如果t中含有p,那么输出yes,如果没有,输出no什么是Hash 那么最重要的问
关联规则挖掘的目的是挖掘不同物品(item)之前的相关性,啤酒和尿布的故事就是一个典型的成功例子。关联规则挖掘思想简单高效,在广告推荐领域也有较多的应用,主要用于推荐模型落地前的流量探索以及构建规则引擎探寻高价值流量等。本文主要介绍关联规则挖掘常用的两种算法,即Aprior算法和Fpgrowth算法。
最近入职之后,带我的导师给我安排了一个活,要搭建一个ucloud2bigquery的数据pipline,理所当然的要用到服务器,于是乎,踩了好多好多坑,害。 公司给的服务器是linux系统,centos版本。我实现这个pipline打算用python3,但是root的python环境是2.x,因此需要自己装环境。强调:如果不是非得用crontab跑脚本,只是开发的话,不建议自己去配,你都不知