- @leafff123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
训练大型语言模型(LLM)不仅依赖于强大的计算能力,还离不开成千上万 GPU 之间高速、低延迟的协同通信。本文将从基础讲起,带你了解训练过程中的通信挑战、横向扩展与纵向扩展、网络架构以及交换机设计等关键知识点。

RAG 系统优化是提升检索增强生成技术性能的重要环节,Multi-Query Retrieval、RAG-Fusion 和 Decomposition Retrieval 都是其中的关键方法。
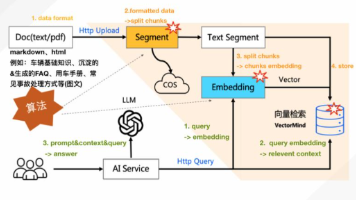
在 AI 技术飞速迭代的当下,“AI Agent(智能体)” 成为备受瞩目的热点,被视为推动 AI 从 “问答工具” 迈向 “自主工作伙伴” 的核心方向。但很多人疑惑,AI Agent 的 “自主行动能力” 从何而来?它如何安全、高效地调用各类工具和数据?这就不得不提到另一个关键角色 ——MCP(Model Context Protocol)。

在不影响画质的前提下优化 AI 短视频制作的算力,核心在于针对视频 “时间连续性” 的特性减少冗余计算,同时保持单帧画质与帧间连贯性。以下是结合视频生成特点的针对性策略

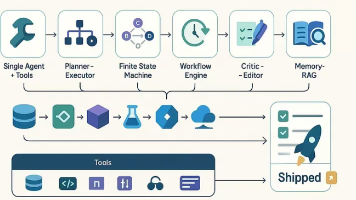
你见过不少 Agent 承诺上天入地,结果却在起跑线上就卡住。真正能交付的关键不在于模型更大,而在于结构——清晰的目标、确定性的工具,以及能闭环的反馈机制。以下这八种架构,是我亲眼见证过能持续推动任务进入“已完成”状态的方案。
LangGraph、Autogen 和 CrewAI 都是当前主流的多智能体开发框架,但它们的设计理念、核心定位和适用场景存在显著差异

如果说大语言模型(LLM)是赋予了AI一个“聪明的大脑”,那么AI Agent(智能体)则是为这个大脑配上了“手脚”,使其能够感知环境、规划决策、执行任务,真正从“对话机器”迈向“数字员工”。AI Agent的落地,标志着人工智能应用进入了以“自主性”和“行动力”为核心的新阶段。

大语言模型 (LLM) 的训练和推理对硬件算力需求存在数量级差异,训练阶段消耗的算力约为推理的10^4-10^6 倍,具体体现在以下几个方面,大语言模型的训练和推理对硬件算力需求的具体差异的数据支撑如下
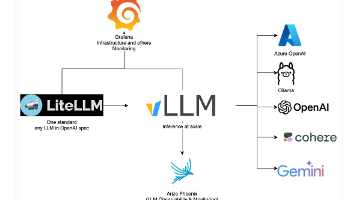
AI Agent(AI 智能体):一种结合人工智能与一系列工具的应用。为体现“智能化”的概念,智能体必须具备三个要素:智能、工具、步骤。三种主流Agent自主编排Agent(Autonomous Agent):一种在启动后能完全独立运行的AI智能体。人机回环Agent(Human-in-the-Loop Agent):一种在运行过程中会向人类发起提示的AI智能体。固定工作流(Workflow):通
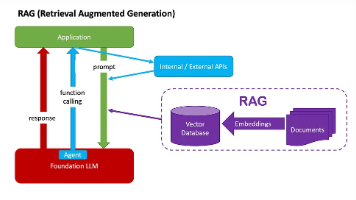
RAG(检索增强生成)系统核心架构模式可归为 4 类,核心逻辑是 “检索外部知识 + 生成式 AI 融合”,解决大模型知识滞后、事实不准确的问题。选择 RAG 架构模式的核心逻辑是 “需求优先级排序 + 资源约束匹配”,优先根据查询复杂度、知识库规模、精准度要求筛选,再结合开发成本、迭代需求最终确定。