




- @jiemo99
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了GSPO(Group Sequence Policy Optimization),一种新型强化学习算法,用于提升大语言模型在复杂任务中的推理能力。传统方法如PPO和GRPO存在训练不稳定、效率低等问题。GSPO创新性地采用序列级优化,通过长度归一化的序列重要性比和整体裁剪机制,显著提高了训练稳定性和效率。实验证明,GSPO在MoE架构和长序列任务中表现优异,已成功应用于Qwen3系列模型

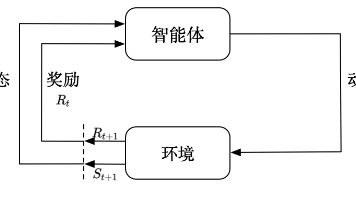
本文介绍了强化学习的核心概念与基础理论框架。首先对比了强化学习(RL)与深度学习(DL)的差异,指出RL以最大化累积奖励为目标,依赖延迟的稀疏反馈和实时交互数据。接着阐述了RL的基本要素:智能体、环境、状态、动作、奖励、策略和回报。文章重点解析了马尔可夫决策过程(MDP)作为RL的数学基础,包括状态转移、奖励函数和折扣因子等核心概念。最后详细介绍了价值函数(状态价值V和动作价值Q)及其递归关系——
首个支持动态思考模式切换的开源大模型→ 一模型通吃简单与复杂任务。119语言支持 + 36T Token训练→ 真正全球化、多领域能力。强到弱蒸馏 + 高效MoE→ 小模型低成本高性能,推动边缘部署。全系列开源 + 完整技术报告→ 社区可复现、可改进、可商用。
问题形式化:给定时间序列多模态输入Mmtτtt1TM{(mtτtt1T,其中mtmt为模态数据,τt\tau_tτt为时间戳,目标是构建函数fM→YfM→Y,使得模型能理解任意时间点的跨模态关联。传统方法将整个音频/视频作为单一特征zaudiozaudio时序分辨率丢失:无法定位"他在说’菜品很冷’时背景有婴儿哭声"长度限制:32K 上下文仅支持 1-2 张图 + 10 秒音频计算效率

阿里巴巴发布Qwen3系列大模型,包含0.6B至235B参数的密集与MoE双架构,支持119种语言并采用36T token预训练。核心创新包括动态思考模式切换(支持/think与/no think指令)、强到弱蒸馏技术(小模型训练成本降低90%)、高效MoE架构(235B参数仅激活22B)以及全系列开源。模型通过四阶段精炼实现复杂推理能力,在数学、代码等任务表现优异,同时提供可控的思维预算功能。技

DeepSeek 稀疏注意力机制(DSA)是一种创新的、由 闪电索引器(Lightning Indexer) 驱动的 动态细粒度稀疏注意力 机制。它将传统自注意力机制的 “选择” 过程与 “计算” 过程解耦,仅对Top-k个最相关的历史词元(Token)进行高精度注意力计算。

上下文窗口(Context Window)指模型单次前向传播可处理的最大输入序列长度,直接影响长文本理解、多轮对话连贯性与复杂推理能力。简单来说就是,上下文窗口:就是大模型的“短期记忆力”——它能一次性处理多少文本内容。4K tokens:约3页A4纸的内容(传统模型)32K tokens:一篇完整学术论文或中篇小说:整本《三体》或专业技术手册1M+ tokens:你过去一年的所有聊天记录或整套法

LongCat-Flash-Chat 重新定义了高效大模型的技术路线——不是盲目堆砌参数,而是通过精巧架构、严谨训练与目标导向优化,在计算效率与模型能力间取得最优平衡。其开源(MIT 许可证)将加速智能体技术在各行各业的落地,推动 AI 从"语言模型"迈向"行动智能"的新阶段。

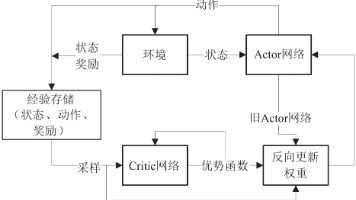
策略梯度算法是强化学习中一类直接优化参数化策略 πθ(a∣s)\pi_\theta(a|s)πθ(a∣s) 的方法,通过计算目标函数(通常是累计奖励的期望)关于策略参数 θ\thetaθ 的梯度,并沿着梯度方向更新 θ\thetaθ。在经典的马尔可夫决策过程(MDP)中,我们的目标是找到一个参数 θ\thetaθ 使得期望累计奖励最大化。对于回合制任务(Episodic Tasks),目标函数可
Gemma 3 是 Google 首个支持图像理解的轻量级开源大模型,在消费级硬件上实现 128K 长上下文、多语言、强 STEM 能力,27B 版性能媲美 Gemini 1.5 Pro,同时以系统化安全机制保障负责任部署。
