- @jiangchaobing_2017
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI Agent:从静态工具到动态执行体的进化 AI Agent(智能体)是具备自主决策与任务执行能力的智能系统,其核心特征包括环境感知、目标理解、工具调用和持续优化。不同于传统AI的被动响应模式,AI Agent通过"感知-决策-执行"闭环实现动态任务处理,能自主规划行动路径并实时调整策略。典型架构包含增强LLM(调用外部工具)、链式提示(分步任务处理)和指挥-工人(主从协作)三种模式,适用于代
Transformer模型是自然语言处理领域的革命性突破,其核心创新在于自注意力机制和并行化处理能力。该模型由编码器和解码器组成,通过嵌入层将离散符号转化为连续向量,并引入位置编码保留序列信息。自注意力机制能有效捕捉长距离依赖关系,多头注意力则进一步增强了模型的表达能力。Transformer不仅主导了NLP领域,还扩展到计算机视觉等多个AI子领域。随着BERT、GPT等变体的发展,Transfo
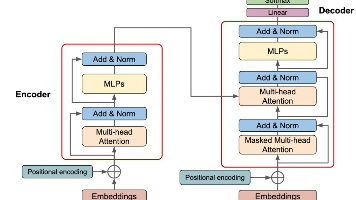
Transformer模型是自然语言处理领域的革命性突破,其核心创新在于自注意力机制和并行化处理能力。该模型由编码器和解码器组成,通过嵌入层将离散符号转化为连续向量,并引入位置编码保留序列信息。自注意力机制能有效捕捉长距离依赖关系,多头注意力则进一步增强了模型的表达能力。Transformer不仅主导了NLP领域,还扩展到计算机视觉等多个AI子领域。随着BERT、GPT等变体的发展,Transfo
大语言模型(LLM)本质上是基于统计预测的文本生成系统,通过Transformer架构处理海量数据,学习语言模式并预测最可能的词语序列。其核心运作包含三个阶段:1)输入文本被分词为token并编码为向量;2)通过自注意力机制和多层Transformer处理上下文;3)以自回归方式逐词生成输出。模型训练采用预训练(学习通用语言规律)和微调(优化特定任务表现)两阶段模式。尽管能生成流畅文本,LLM并不
摘要: DeepSpeech2是一个端到端语音识别模型,采用CNN提取音频特征,RNN处理时序信息,并通过CTC损失函数解决序列对齐问题。在Android应用中,模型推理流程包括音频特征预处理、CNN/RNN计算及CTC解码。示例代码展示了NPU加速的推理实现,包含参数校验、数据量化、模型加载、推理执行及结果后处理等步骤,最终输出识别文本。
例如,run cts --plan CTS将运行所有的测试计划。运行测试类和/或方法:使用run cts --class/-c class_name [–method/-m method_name]命令可以运行特定的测试类或方法。在指定设备上运行测试:使用run cts [options] --serial/-s device_ID命令可以在指定的设备上运行CTS测试。运行测试包:使用r

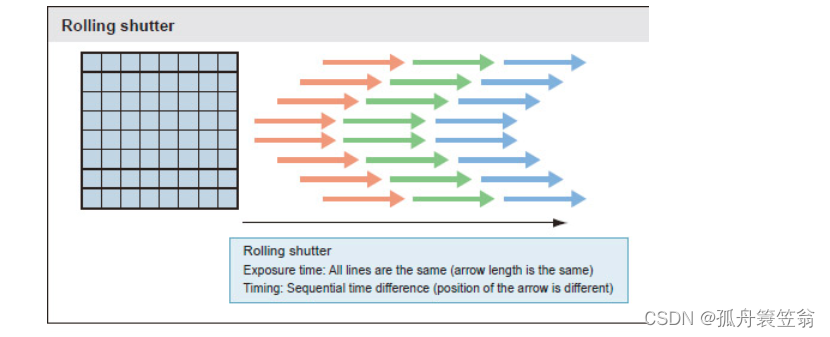
AE是一种自动调节曝光时间的机制,其主要功能是在外界环境光照条件发生变化时,通过调节sensor的曝光时间、光圈大小、增益等参数,使图像或视频保持适当的亮度,防止过曝或过暗导致的细节丢失。N段式统计法是一种有效的自动曝光策略,它能够在保证预览帧率的同时,尽可能地减小噪点的影响,并在不同的光线条件下获得较为理想的图像亮度。与全局曝光(Global Shutter)不同,卷帘曝光是逐行进行的,即从图像
需要注意的是,SELinux的工作模式可以在/etc/selinux/config文件中进行配置。在此模式下,SELinux仍然监控所有进程和文件访问,但即使检测到违反策略的行为,也不会阻止它们。SELinux(Security-Enhanced Linux)有三种主要的工作模式,这些模式决定了SELinux在系统上实施安全策略的方式。此外,SELinux日志的记录需要借助auditd.servi
1.2.1 对于杂音类问题,只需听pcm dump是否有杂音即可确认问题端发生在应用层,如果in.pcm已存在杂音,则问题可能存在于audio hal之前,如audio service、软件编解码器、或者音源本身存在杂音;如果控件没有差异,可在播放时,dump一下寄存器并作对比,将升级前后的寄存器dump上传到Aservice供进一步分析,如果没有差异,则需寄板子、上传原理图与位号图,进行进一步排

因为系统中可能存在多个音轨同时播放,而每个音轨的采样率可能是不一致的,比如在播放音乐的过程中,来了一个提示音,这时需要把音乐和提示音混音并输出到硬件设备,而音乐的采样率和提示音的采样率不一致,问题来了,如果硬件设备工作的采样率设置为音乐的采样率的话,那么提示音就会失真,因此最简单见效的解决方法是:硬件设备工作的采样率固定一个值,所有音轨在 AudioFlinger 都重采样到这个采样率上,混音后输