




- @hlayumi1234567
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第一,混沌是固有的,系统所表现出来的复杂性是系统自身的,由内在因素决定的,并不是在外界干扰下产生的,是系统的内在随机性的表现。其次,混沌及其理论混沌的表现是貌似随机,而并不是真正的随机,系统的每一时刻状态都受到前一状态的影响,是确定出现的,而不是像随机系统那样随意出现,混沌系统的状态是可以完全重现的,这和随机系统不同。从某种意义说,混沌应是一门关于过程的科学不是一门关于状态的科学,是一门关于演化的
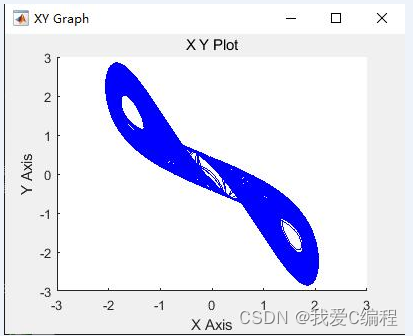
matlab2022a仿真结果如下仿真操作步骤可参考程序配套的操作视频。低密度奇偶校验码(Low-Density Parity-Check Codes,LDPC)是一种具有逼近香农限性能的信道编码技术。在现代通信系统中,LDPC 码因其优异的性能而得到了广泛的应用。BP(Belief Propagation)译码算法是 LDPC 码的一种重要译码方法,它通过在 Tanner 图上进行消息传递来实现
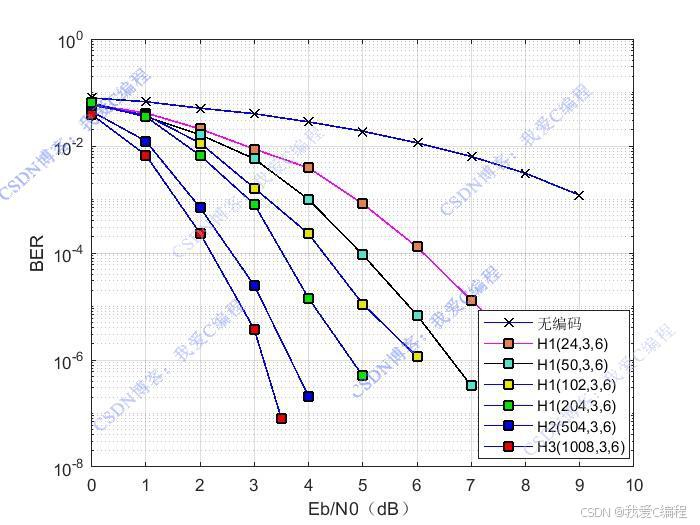
本文摘要:本文研究了接近香农极限的Polar码和LDPC码的编译码原理及性能仿真。详细介绍了Polar码的信道极化过程和SCL译码算法,以及LDPC码的BP译码原理。在MATLAB2024b环境下实现了两种编码的仿真,通过对比分析验证了它们接近香农极限的性能特性。研究结果表明,Polar码在理论性能上可达香农极限但需长码长,而LDPC码在中等码长下即可接近极限。仿真代码可完整运行并生成无水印结果,

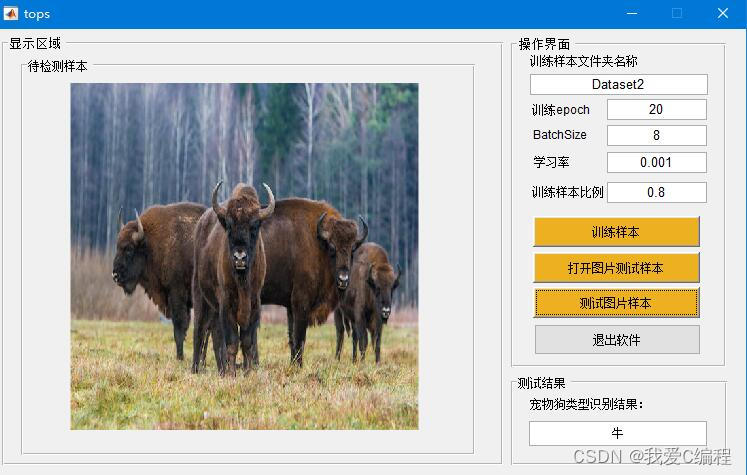
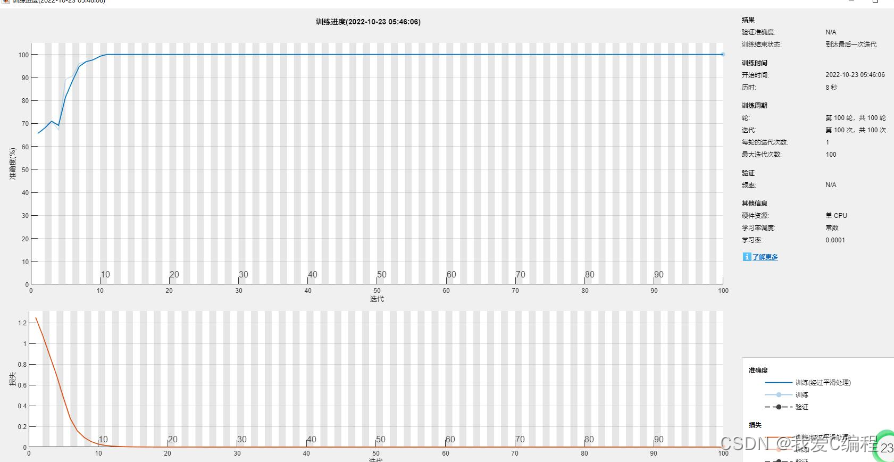
训练的过程是通过反复迭代输入图像和对应的标签,不断调整CNN的权重,以使得CNN在给定的任务(动物识别)上达到最佳的性能。CNN是一种特别适合处理图像数据的神经网络,其通过一系列的卷积层、池化层和全连接层来提取和识别图像中的特征。训练好的CNN模型可以识别出训练集中出现的动物,并且能够将其在图像中的位置标注出来。为了提高模型的性能,通常需要对训练数据进行增强和预处理。总的来说,基于深度学习网络的动
该网络的输入是接收到的信号样本,输出是估计的相位偏移量。相位检测的目标是从接收到的信号中估计出相位偏移量。相位补偿的目标是根据估计出的相位偏移量对接收到的信号进行校正,以消除相位偏移的影响。传统的补偿方法通常是通过旋转接收到的信号来实现的。具体来说,可以在神经网络的输出端添加一个旋转矩阵,该矩阵根据估计出的相位偏移量对接收到的信号进行旋转校正。这样,神经网络的输出就是经过相位补偿后的信号,可以直接
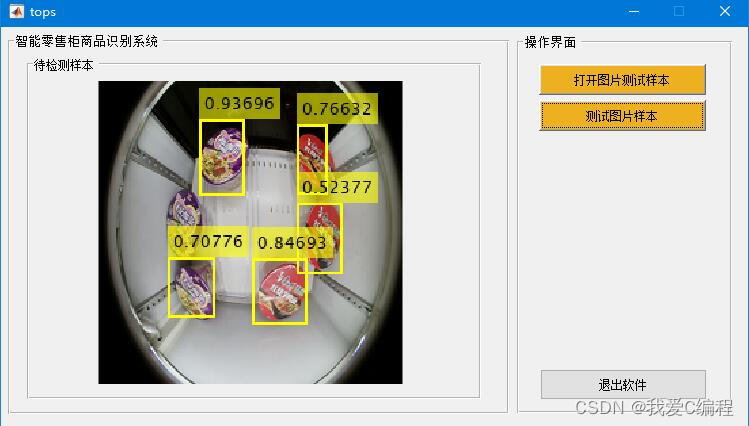
当部署在零售柜时,摄像头拍摄的实时画面会被送入YOLOv2网络,网络将整幅图像划分为多个网格,每个网格负责预测一定数量的边界框及其所属商品的类别概率。YOLOv2采用了端到端的方式直接从整幅图像预测边界框和类别概率,极大地提高了检测速度。55代表每个边界框的坐标信息(x,y,w,h,confidence),其中(x,y)是边界框的中心相对于网格单元的位置比例,w,h是边界框的宽度和高度相对于整幅图
单个PCNN神经元的滤波特性由馈电输入的模式和应用于这些输入的权重决定。图4显示了PCNN中单个神经元的框图。PCNN是Eckhorn于20世纪90年代开始提出的一种基于猫的视觉原理构建的简化神经网络模型,与BP神经网络和Kohonen神经网络相比,PCNN不需要学习或者训练,能从复杂背景下提取有效信息,具有同步脉冲发放和全局耦合等特性,其信号形式和处理机制更符合人类视觉神经系统的生理学基础。在该

考虑一个基于64QAM调制的单载波通信系统,其中发送端将输入比特流映射为复数符号,经过上变频、信道传输和下变频等过程后,接收端对接收到的符号进行解调和判决,得到输出比特流。基于深度学习的64QAM调制解调系统的频偏估计和补偿算法主要通过构建并训练神经网络模型来实现精确的频偏感知,并结合传统的数字信号处理技术完成补偿,从而提高通信链路的整体性能。基于深度学习的频偏估计和补偿算法利用深度神经网络来建立
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。第一个卷积神经网络计算模型是在Fukushima(D的神经认知机中提出的,基于神经元之间的局部连接和分层组织图像转换,将有相同参数的神经元应用于前一层神经网络的不同位置,得到一种平移不变神经网络结构形式。与传统的学习方法相比,深度学习方法预设了更多的模型参数,因此模
在OFDM系统中,信道估计器的设计上要有两个问题:一是导频信息的选择,由于无线信道的时变特性,需要接收机不断对信道进行跟踪,因此导频信息也必须不断的传送: 二是既有较低的复杂度又有良好的导频跟踪能力的信道估计器的设计,在确定导频发送方式和信道估计准则条件下,寻找最佳的信道估计器结构。非盲信道估计方法通常采用插入训练序列的方式或者插入导频的方式,盲信道估计方法则是在接收端采用相应的信号处理技术来获得
