




- @hknaruto
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下载地址官方下载地址是github提供的下载服务,务必保持网络与github的连通性。国内加速地址原地起飞安装安装完成,自动弹出窗口可以看到,ollama支持自动配置claude code等多种智能体程序,非常方面。
这篇文章探讨了两个同名但功能完全不同的开源项目"Anaconda"带来的混淆问题。一个是Linux系统安装程序(用于Fedora/RHEL等发行版),另一个是Python数据科学平台。作者详细分析了两者的区别:Linux Anaconda是用Python编写的系统安装工具,运行在操作系统之前;而Python Anaconda是包含conda、Jupyter等工具的数据科学套件,运行在操作系统之上。
买不起高端GPU,但又无法忍受弱智模型的劣质答案。安全与智能的解耦:将“存数据”与“算数据”分离。数据存本地保安全,计算上云端保智商。经济性极佳:利用DeepSeek V4 Flash的超低价(1元/百万输入)和语义缓存机制,将年度API成本控制在可接受的范围内,避免了数十万的A100显卡采购费用。主流模型护航:依托DeepSeek、MiniMax、Kimi等国内一线大厂的SOTA模型,智力水平直
安装libgl修改Makefile GL_LIBS,差异如下编译。
改用powershell解决。

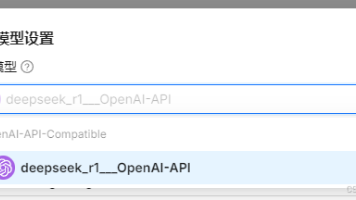
更新系统模型设置,可以看到添加的本地模型了。
ClickHouse部署与游戏数据分析模拟 本文介绍ClickHouse数据库的Docker部署方法,包括镜像拉取、容器启动和数据目录挂载。提供了查看自动分配端口的方法和端口说明(8123用于HTTP接口,9000用于原生客户端)。同时展示了如何使用CLI客户端和curl工具连接数据库,并说明修改密码的方法。 文章还模拟了游戏Command Modern Operations的事件数据分析场景,创
DeerFlow智能体迁移指南摘要 DeerFlow是字节跳动开源的超级智能体编排框架,基于LangGraph重构,提供完整智能体开发套件。相比原生LangGraph,DeerFlow内置了Web界面、沙箱执行、持久化记忆等企业级功能。系统采用分层架构,包含LangGraph运行时、Gateway API和中间件链等核心组件。 迁移实施需分五步:1)评估现有智能体结构;2)将节点封装为Skill;
总而言之,配置三个模型变量是 Claude Code 的一项精细化控制设计。它允许系统根据不同任务智能选择最合适的模型,从而在性能、速度和成本之间实现最佳平衡。你可以根据实际需求,为不同场景指定不同的模型。Opus:用于复杂的架构和推理任务。Sonnet:作为日常编码的主力模型。Haiku:用于快速的简单查询和补全。当然,如果你希望在所有场景下都统一使用一个模型,也完全可行。
买不起高端GPU,但又无法忍受弱智模型的劣质答案。安全与智能的解耦:将“存数据”与“算数据”分离。数据存本地保安全,计算上云端保智商。经济性极佳:利用DeepSeek V4 Flash的超低价(1元/百万输入)和语义缓存机制,将年度API成本控制在可接受的范围内,避免了数十万的A100显卡采购费用。主流模型护航:依托DeepSeek、MiniMax、Kimi等国内一线大厂的SOTA模型,智力水平直