




- @guslegend
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
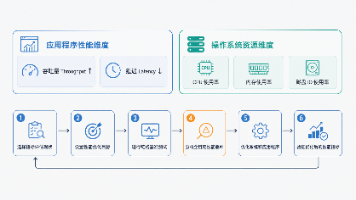
本文摘要:文章系统性地介绍了操作系统与网络的核心知识点,重点涵盖计算机硬件组成、操作系统功能、进程线程管理、调度算法及性能优化方法论。首先解析了冯诺依曼架构的五大组成部分,详细说明了进程状态转换和线程资源共享机制,对比了六种进程调度算法的特点及适用场景。在性能优化方面,提出了从吞吐量和延迟两个维度进行分析的诊断方法,结合CPU、内存、磁盘IO等资源指标建立优化体系。网络部分涉及TCP/IP模型、H
一个稳定、高效、安全的用户中心,不仅能为用户提供流畅的使用体验,更能为飞算 AI 的业务拓展、数据管理和安全防护奠定坚实基础。该项目以 “便捷管理、安全可靠、灵活扩展” 为核心目标,通过构建涵盖用户登录、退出、信息增删改查的完整体系,实现对用户全生命周期的精细化管理,为飞算 AI 的业务升级提供有力支撑。设计优势:通过UNIQUE约束避免数据重复,TIMESTAMP类型字段支持时间维度的数据分析,
摘要:大模型存在知识滞后、能力边界、计算短板等原生局限性,无法直接获取实时信息或连接业务系统。工具调用(FunctionCall)作为LLM与外部交互的接口,能扩展AI能力、实现流程自动化并保障安全。SpringAI提供统一工具调用解决方案,通过@Tool注解定义功能,由FunctionCallAdvisor自动处理调用流程。示例展示了通过自然语言查询天气的多工具协调实现,验证了该方案在实时数据获

本文介绍了JSR107缓存规范和Spring Cache缓存抽象的使用。JSR107定义了缓存的核心接口(CachingProvider、CacheManager等),而Spring Cache通过@Cacheable、@CachePut等注解实现了声明式缓存管理。文章详细说明了缓存注解的属性和用法,包括缓存条件、键生成策略等,并提供了数据库环境搭建和Redis缓存配置的实例。最后针对Redis缓

SpringBoot项目部署与监控实践摘要 本文介绍了SpringBoot项目的两种打包部署方式:jar包适合独立运行的REST服务项目,通过java -jar命令直接启动;war包适合包含大量静态资源的项目,需部署到Tomcat容器。详细说明了两种方式的配置差异和启动类改造要点。同时探讨了多环境部署方案,包括@Profile注解和资源文件配置。重点讲解了SpringBoot Actuator监控

本文介绍了Python环境配置与智能体开发相关内容。首先详细说明了Anaconda的安装资源及与Miniconda的区别,并提供了UV包管理工具的安装方法(支持镜像加速配置)。其次,阐述了智能体开发流程,包括:1)本地大模型部署(通过Ollama运行Deepseek模型);2)云端大模型调用(阿里云百炼);3)流式响应实现。最后介绍了LangChain框架的四层架构(核心层、应用层、社区层、合作伙

摘要:本文介绍了四种LangChain提示词模板的使用方法,包括基本PromptTemplate(用于标准化文本生成)、Placeholder(处理多轮对话历史)、FewShot(通过示例引导模型输出)和FewShotChat(对话风格示例)。这些模板能有效提升开发效率,适用于产品描述、客服回复、分类任务等场景。文中提供了每种模板的代码示例和注意事项,强调变量命名一致性、特殊字符转义、示例简洁性等
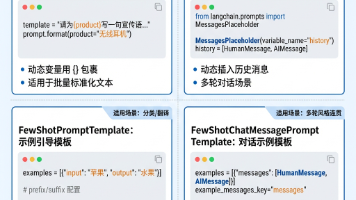
本文系统介绍了Prompt Engineering的核心概念与实践方法。首先解释了Prompt和Prompt Engineering的定义,强调清晰、具体、可执行的写作原则。重点介绍了角色扮演技巧、通用四要素框架(指令+背景+输入+输出)以及10种学习场景模板(如费曼学习法、番茄工作法等)。还详细说明了输出格式控制(Markdown/JSON等)和Playground参数设置。文章提供了可直接复用
OCR技术演进与多模态应用:从传统字符识别到结构化文档理解 本文系统梳理了OCR技术从传统字符识别到多模态理解的演进历程。传统OCR(1.0)基于CNN+LSTM架构,专注于文字检测与识别;而现代OCR(2.0)融合视觉Transformer、布局分析和视觉语言对齐技术,实现了语义理解和结构化输出。以GPT-4V、Gemini等为代表的多模态大模型(VLM)进一步推动了OCR向文档理解发展,使其具
比如搜集每日专业相关的资讯和资料、做竞品分析、按照公司要求的格式写周报和整理会议纪要、给客户写跟进邮件等等,只要流程基本固定,且输出格式可预期,就都是好的 Skill 候选。“帮我做个分镜”、“把这个故事拆成分镜”、“生成分镜脚本”,把这些你可能会用的表达都写进 description 里,AI 才能准确识别,下次你一说它就触发。Memory 机制的初衷是好的,但时间长了会积累大量过时的、低价值的
