- @gallopingdb
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
要取得CC EAL4+认证, 首先要完成安全目标 (ST) 描述,包括对产品整体架构和产品安全功能的概述、对潜在安全威胁的评估以及自我评估测试,并通过ARC、FSP、TDS、ALC等系列文档对整个产品的架构、接口、功能和研发流程进行精细化描述,其次需由有许可的独立实验室完成产品安全功能测试及验证,并评估其是否符合通用安全标准。该标准设置了EAL1~EAL7的不同评估等级,等级越高,评估要求的证据越
该版本将在集团、科技、物流等业务系统广泛应用,也将服务更多的外部行业客户,同时我们也进一步加强与openGauss社区的共建和创新,共建底层的内核能力,打造统一的上层生态,推动新硬件的应用创新,促进社区的繁荣发展。openGauss生态蓬勃发展,实现关键行业全覆盖。经过2年多的发展,openGauss凝聚产业力量,发展进入快车道,目前有超过185家企业加入社区、社区贡献者达到4000+,累计商用达

在从oracle迁移到openGauss中,创建函数索引的时候,偶尔会出现此类报错大概意思是,函数索引里的函数,必须是“IMMUTABLE”的,如果不是"IMMUTABLE",比如是“STABLE”,就会出现这个报错。其中最常见的就是使用to_char/to_date这两个与日期有关的函数,而此限制,在原生PG中也同样存在。
函数依赖,是多列统计信息的一种,可以描述属性之间的关联关系,其主要用途是提高选择率估算的准确性。",此时的转移状态初始化后为两个参数(total, count),然后遍历表的所有元组,total执行累加操作,count执行自增操作,最后把total/count和total分别作为avg函数和sum函数的返回结果。新型选择率模型充分利用基于直方图的统计信息,平衡计算量与准确性,充分考虑数据分布情况,
要想社区长期保持活力,离不开群策群力治理社区。在技术演进上,江大勇表示,数字技术正在加速落地行业应用,支撑丰富的在线应用与服务,产业数字化加速产生海量的数据,数据类型多样(图、流、时序和地图空间等),这背后需要不同的算力架构支撑处理,当下数据库对计算的需求由单一通用的 CPU 向 GPU、NPU 等多样性计算演进。在 2021 年 openGauss Summit 峰会上,openGauss 提出

具体来说,图模型中的每个节点都是一列数据,节点之间的边表示节点之间的相关关系。而对于更多列的联合分布,为了避免指数级别的空间复杂度增长,openGauss采用了条件独立性假设,比如三列数据X,Y,Z分布相关,但是一旦将Y取值固定,X和Y的分布便称为独立,这时的联合概率计算可以被抽象为P(X,Y,Z)=P(X|Y)P(Y|Z)P(Z)。当前数据库为了高效估计多列复合查询条件的基数,广泛采用了基于独立
多云2.0时代,云基础资源已经成为信息系统的水电煤,Squids openGauss旨在将弹性灵活的云资源和openGauss卓越的数据库功能结合,为用户提供完整的云上数据库新体验,平台会以开放,中立,简洁,高效的形态,服务广大开发运维人员,帮助用户真正迈入多云时代。针对临时性的测试体验需求,利用竞价实例+云盘+对象存储,构建弹性数据库环境,非测试期间可以一键释放计算实例节省成本,后续使用可一键式
相对于逻辑优化,这种优化方法是物理优化:根据数据的分布(统计信息)情况来对查询执行路径进行评估,从可选的路径中选择一个执行代价最小的路径进行执行,例如是否选择索引SeqScan vs. IndexScan,选择哪个索引,两表关联选择什么样的连接顺序,选择怎样的具体算法等。在代价估算时,需要使用基表或连接表的行数,而在很多时候,优化器无法获得准确的行数值,因此需要对行数进行估算(Cardinalit
openGauss实现了两种算法进行索引优选:一种是在限定索引集大小的条件下,根据索引的收益进行排序,然后选取靠前的候选索引来最大化索引集的总收益,最后采用微调策略,基于索引间的相关性进行调整和去重,得到最终的推荐索引集合;虚拟索引主要是基于数据库中的hook(钩子机制)实现的,即通过使用全局的函数指针get_relation_info_hook和explain_get_index _name_h

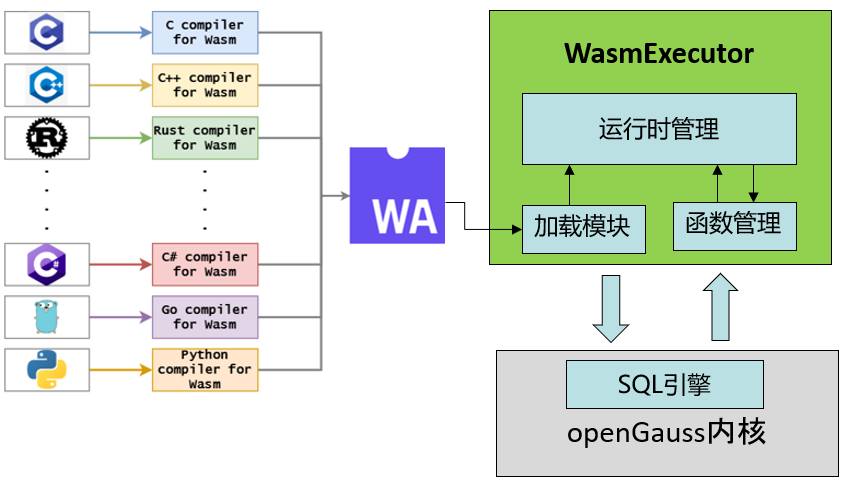
如下,我们使用 wasm_new_instance 和 wasm_new_instance_wat 来分别加载 sum.wasm 和 fib.wat 中的函数,在加载函数文件时,提供函数放置的名称空间 namespace,方便进行函数管理,最终注册到 openGauss 系统表中的函数名称将会是 namespace_funcname 的新名称。可以看出,即便在计算量比较小的场景下,Wasm 的执行