




- @forwujinwei
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
部分代码是搬别人写好、自己做了调整一、认证服务器配置1.新建maven项目pom.xml<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId&g...
1 永久性生效,重启后不会复原开启: chkconfig iptables on关闭: chkconfig iptables off2 即时生效,重启后复原开启: service iptables start关闭: service iptables stop查询TCP连接情况:netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(...
废话不多说,直接上代码1.先创建一个base64编码类,实际项目中不用自己写,有成熟的实现方法package com.taikang;public final class Base64 {static private final intBASELENGTH= 128;static private final intLOOKU...
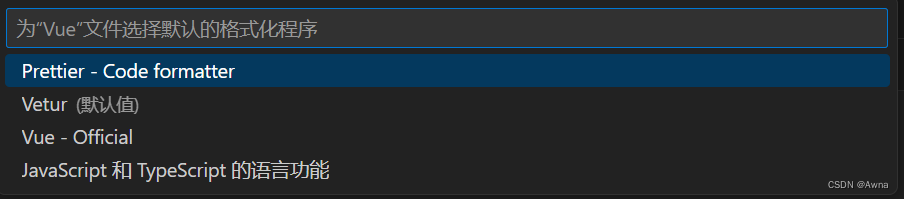
所有配置都配好了就是无法使用自己想要的vetur格式化代码。后台发现调整默认格式化代码的顺序就可以,
一、hystrixhttps://blog.csdn.net/zjcsuct/article/details/78198632二、实现方式1.通过注解实现2.AOP实现3.继承方式实现三、hystrix监控1.单机监控修改项目配置1、pom.xml<dependency><groupId>com.n...
{// 如果此设置为 false,则无论新设置的值如何,都不会发送遥测数据。由于合并到 `telemetry.telemetryLevel` 设置,目前已弃用。// 启用要收集的崩溃报告。这有助于我们提高稳定性。// 此选项需重启才可生效。"telemetry.enableCrashReporter": true,// 如果此设置为 false,则无论新设置的值如何,都不会发送遥测数据。已弃用,推

*RAG(Retrieval-Augmented Generation,检索增强生成)**是一种结合信息检索和生成式AI的技术架构,通过从外部知识库中检索相关信息来增强大语言模型的生成能力,从而提高回答的准确性和可靠性。
随着人工智能技术的快速发展,相关的专业术语和概念也日益丰富。对于初学者来说,这些术语可能会让人感到困惑。本文将为您介绍一些常见的AI相关专有名词,帮助您更好地理解这个领域。
这些问题看起来琐碎——模型存在哪?怎么装依赖?重复跑会怎样?但正是这些"小问题"构成了真正的理解。会跑脚本不等于懂模型,就像会开车不等于懂发动机。但当你知道油箱在哪、变速箱怎么工作、为什么不能一直踩油门不换挡——你就从"会开车"变成了"懂车的人"。微调模型也是一样。知道权重存在哪、每次训练从哪个起点出发、为什么不能无脑叠加训练——这些才是让你从"跑通了脚本"变成"真正掌握了微调"的关键。