




- @feifeikon
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
平滑:对所有可能出现的字符串都分配⼀个不为0的值,防⽌出现概率为0。预训练⼤语⾔模型PLM参数巨⼤,在不同任务上都进⾏微调代价巨⼤。可以通过过语境学习(In context Learning,ICL)等⽅法,直接使⽤⼤规模语⾔模型就可以在下取得很好的效果。

(Norm Enforcement with a Soft Touch,即“柔性规范执行”),这是一个。在多智能体系统(multiagent system, MAS)中,智能体之间的交互可通过。可能在促进多智能体系统中的**合作(cooperation)**方面更为有效。智能体对其他智能体的行为作出反应,可能表现为对满意或不满意行为的。对 Nest 进行了实验评估,并考察了三种不同的。,这种方式更

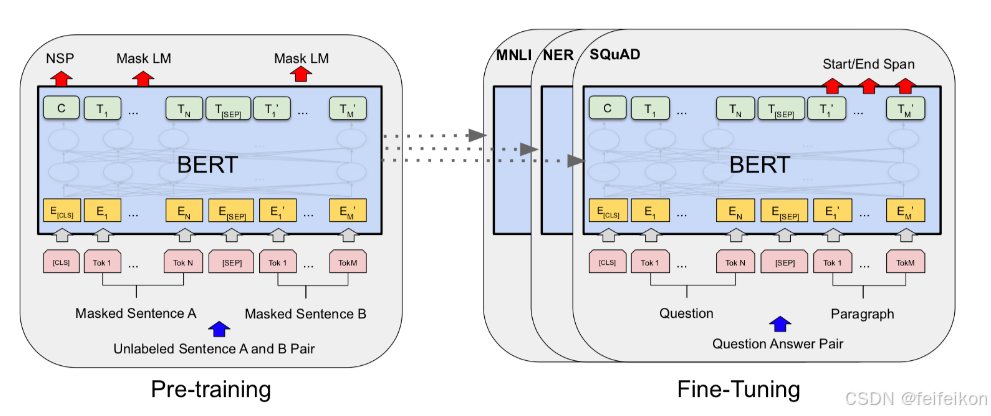
先说结论:BERT其实真没干啥。BERT其实就是在Transformer的基础上,只用了encoder部分,然后在输入端多了一个Segment Embedding(创新点1),用了两个预训练任务(Masked Language Model (MLM))和 Next Sentence Prediction (NSP)(创新点2),然后就没了,就这两个创新点
GRPO的核心思想是通过组内相对奖励来优化策略模型,而不是依赖传统的批评模型(critic model)。具体来说,GRPO会在每个状态下采样一组动作,然后根据这些动作的相对表现来调整策略,而不是依赖一个单独的价值网络来估计每个动作的价值。这种方法的优势在于:减少计算负担:通过避免维护一个与策略模型大小相当的价值网络,GRPO显著降低了训练过程中的内存占用和计算代价。提高训练稳定性:GRPO通过组

如今,我们已经了解了 PyTorch 中张量及其运算,但这远远不够。本次实验将学会如何使用 PyTorch 方便地构建神经网络模型,以及 PyTorch 训练神经网络的步骤及方法。

其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好
GPT-2继续沿用了原来在GPT中使用的单向 Transformer 模型,尽可能利用单向Transformer的优势,做一些BERT使用的双向Transformer所做不到的事。那就是通过上文生成下文文本。GPT-2的目标是为了训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络机构进行过多的结构创新和设计,只是使用了更大的数据集和更大的网络参数。
大型语言模型(LargeLanguageModels,LLMs)的兴起[8][9],特别是那些增强了多模态能力的模型[10],为GUI自动化带来了颠覆性变化,重新定义了智能体与图形用户界面交互的方式。我们将回顾GUI智能体的发展历史,提供构建这些智能体的分步指南,汇总基本和高级技术,评审与框架、数据和模型相关的重要工具和研究,展示典型应用,并概述未来发展方向。通过这些问题,本综述旨在提供对该领域现

其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好
其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好