- @febwww
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
设计“教师教学能力问卷”,通过专家评审确保题项覆盖“备课能力”“课堂管理”等内容(内容效度),通过因子分析验证题项是否分成“专业能力”和“沟通能力”两个维度(结构效度),并与“学生成绩提升率”(效标)关联,验证问卷有效性。对“客户满意度”的10个题项(如“产品质量”“物流速度”“客服态度”等)进行因子分析,提取出2个潜在因子:“产品体验因子”(与质量、价格相关)和“服务体验因子”(与物流、客服相关

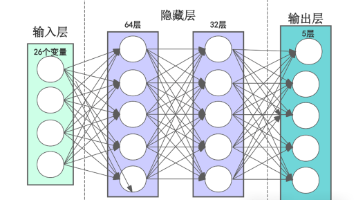
别急着被 “神经网络” 这四个字吓住,其实它很接地气。咱们可以把 BP 神经网络想象成一个 “小型决策团队”。这个团队里有很多 “小成员”(神经元),它们分成好几排(层):最前面的是 “接收信息员”(输入层),负责接收各种数据,比如图片的像素点、声音的波形;中间的是 “分析员”(隐藏层),会对信息进行层层处理;最后面的是 “输出员”(输出层),给出最终结果,比如 “这是张三的脸”“这句话是让打开空
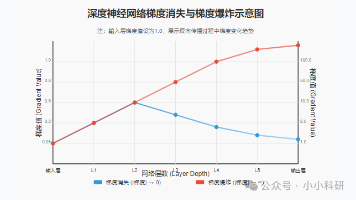
梯度消失与梯度爆炸的本质是梯度在反向传播中的极端累积,解决问题的核心思路是减少梯度的衰减/膨胀,增强梯度的传递能力。深度学习避坑指南:一文搞懂梯度消失与梯度爆炸在神经网络训练中,模型通过反向传播计算来更新参数。当梯度出现异常时,参数更新就会失控,进而导致模型训练失败。二者的本质是梯度在反向传播过程中的极端变化,但表现却截然相反。t=P7R7深度学习避坑指南:一文搞懂梯度消失与梯度爆炸在神经网络训练
如果你也在神经网络的应用中踩过这些坑,那这篇文章可算来对了。RBF、GRNN和PNN这三种神经网络,常被大家放在一起比较,却又总让人摸不清它们的用法。今天咱们就从模型特点到参数设置,再到实际应用,把这三者扒得明明白白,帮你避开选择困难症,高效用对模型!

梯度消失与梯度爆炸的本质是梯度在反向传播中的极端累积,解决问题的核心思路是减少梯度的衰减/膨胀,增强梯度的传递能力。深度学习避坑指南:一文搞懂梯度消失与梯度爆炸在神经网络训练中,模型通过反向传播计算来更新参数。当梯度出现异常时,参数更新就会失控,进而导致模型训练失败。二者的本质是梯度在反向传播过程中的极端变化,但表现却截然相反。t=P7R7深度学习避坑指南:一文搞懂梯度消失与梯度爆炸在神经网络训练
如果你也在神经网络的应用中踩过这些坑,那这篇文章可算来对了。RBF、GRNN和PNN这三种神经网络,常被大家放在一起比较,却又总让人摸不清它们的用法。今天咱们就从模型特点到参数设置,再到实际应用,把这三者扒得明明白白,帮你避开选择困难症,高效用对模型!
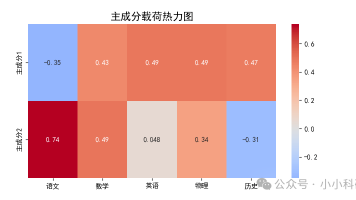
主成分1的学生可能在主科(语文数学英语)中表现较差,在物理、历史科目上表现较优,主成分2的学生可能在主科上表现较优,在物理和历史科目上略逊一筹。更像 “潜在规律探测器”,其数学模型为:x=Λf+ϵ其中,x是可观测的p维变量向量,Λ为因子载荷矩阵,f是m维不可观测的潜在因子向量(m<p),ϵ是特殊因子向量,代表无法被潜在因子解释的部分。如下图,A_包装与 B_设计在图中聚集(对应 “外观评价因子”)
维度线性规划(LP)非线性规划(NLP)整数规划(IP/0-1 规划)函数形式目标函数和约束均为线性至少一项为非线性通常为线性(非线性更复杂)决策变量取值连续实数连续实数整数(0-1 规划为 0 或 1)可行域凸多面体(连续、凸集)可能为非凸集(连续)离散点集(非连续)最优解特性存在时必在顶点上可能有多个局部最优解需在离散点中搜索求解难度低(有成熟高效算法)高(无通用算法,依赖问题特性)高(离散性
什么是 KNN?一句话看懂核心逻辑KNN 的全称是 K-Nearest Neighbors,翻译过来就是 “K 近邻算法”。它的思路简单到让人惊讶:当要判断一个新事物的类别时,只需要看看它周围最近的 K 个 “邻居” 是什么类别,然后跟着多数派 “站队” 就行。举个例子:假设你不知道 “猕猴桃” 是什么水果,但你发现它周围最近的 3 个水果(K=3)里,有 2 个是 “浆果”、1 个是 “核果”,