




- @dc_young
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
PPO1算法通过引入KL散度惩罚项来约束策略更新的幅度,确保新策略不会偏离旧策略太远。这种方法的主要优点是提供了理论上的稳定性保证,适合对安全性要求高的应用。主要缺点是计算相对复杂,需要计算KL散度并自适应调整惩罚系数,这增加了实现难度和计算开销。PPO2算法通过裁剪机制约束策略更新幅度,在保持训练稳定性的同时实现了高效优化。实现简单,无需复杂约束优化计算高效,适合大规模应用超参数少,易于调参在大
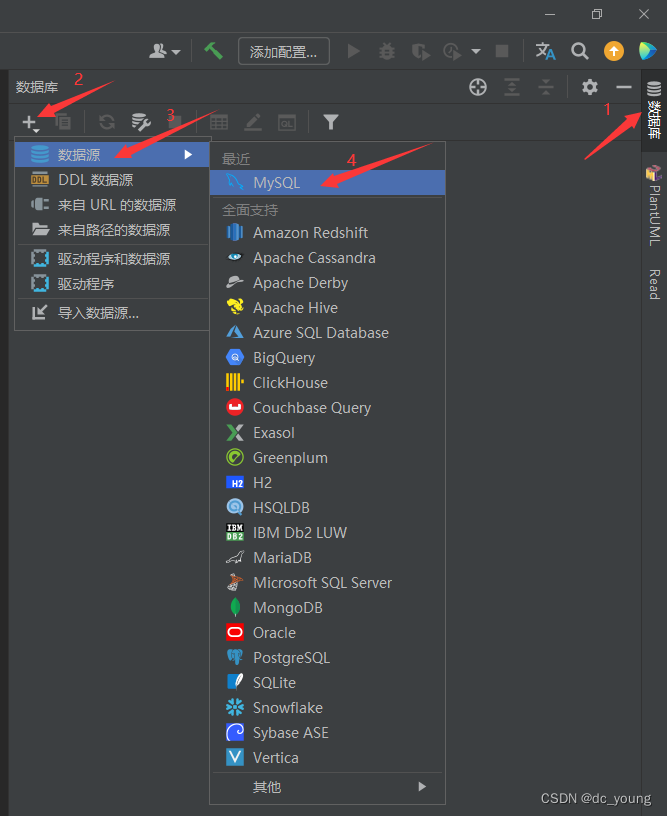
首次使用需要下载驱动程序,不然连接数据库会报错。找到mysql,点击驱动程序文件下面的加号,点击提供的驱动程序,选择mysql驱动程序(mysql connector/J),然后选择驱动版本。如果安装的mysql是5版本,下载那个都可以,如果安装的8版本就下载8版本的驱动程序。驱动程序下载完成之后选择类,5版本mysql就选择图中的类com.mysql.jdbc.Driver。如果mysql是8版
1999 年,Andrew Ng、Daishi Harada 和 Stuart Russell 在 ICML 发表了经典论文。我们能否修改奖励函数,让学习更快,但又不改变最优策略?论文给出的核心答案是:除了正线性变换之外,若要“普遍地”保持最优策略不变,附加奖励必须具有一种特殊结构——。很多强化学习实践者第一次接触 reward shaping 时,会把它理解成“多给点中间奖励”。这当然没错,但也
如何让机器人面对开放式自然语言指令时,先做出正确的长时程规划,再由底层控制器逐步执行,并在执行过程中持续判断当前步骤是否完成。缺少大规模、真实世界、顺序化、语言条件的规划数据。缺少适合强化微调的、可验证且可扩展的奖励函数。即使能离线生成计划,也往往缺少在线执行中的完成判断与失败后重规划能力。为了解决这些问题,论文提出了REVER(Reinforced Embodied Planning with
首次使用需要下载驱动程序,不然连接数据库会报错。找到mysql,点击驱动程序文件下面的加号,点击提供的驱动程序,选择mysql驱动程序(mysql connector/J),然后选择驱动版本。如果安装的mysql是5版本,下载那个都可以,如果安装的8版本就下载8版本的驱动程序。驱动程序下载完成之后选择类,5版本mysql就选择图中的类com.mysql.jdbc.Driver。如果mysql是8版