




- @dajiangtai007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
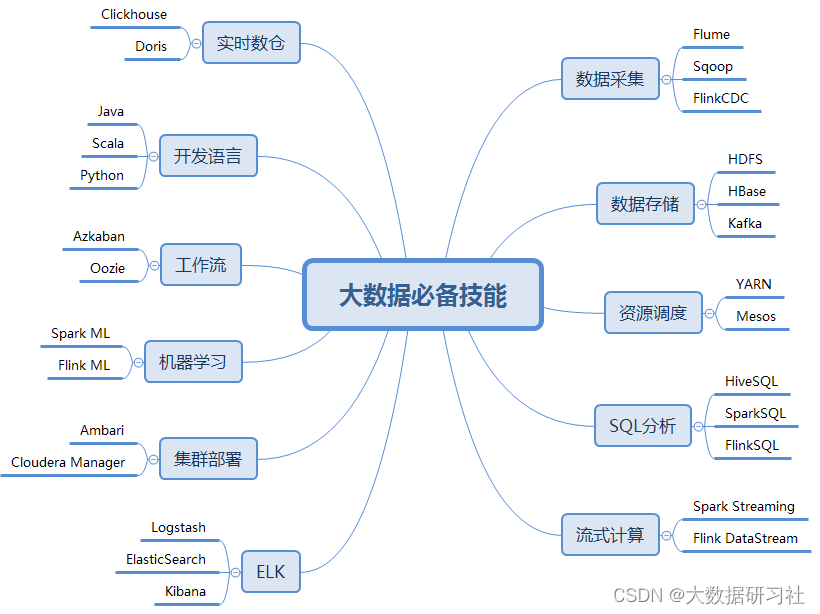
课程介绍本课程是由猎豹移动大数据架构师,根据Java在公司大数据开发中的实际应用,精心设计和打磨的大数据必备Java课程。通过本课程的学习大数据新手能够少走弯路,以较短的时间系统掌握大数据开发必备语言Java,为后续大数据课程的学习奠定了坚实的语言基础。适用人群1.想学大数据没有语言基础的学员2.想学大数据没有Java语言基础的学员3.转行想学大数据的学员4.了解Java,大数据Ja...
本人目前是一名大数据高级工程师,项目数据容量100P+,日处理数据量200T+,集群规模1000+节点,个人是Java前后端开发,因公司项目开发需要,边学习边做项目,四个月成功完成公司项目并成功转型大数据工程师,后经过长时间积累先后著书《实战大数据(Hadoop+Spark+Flink)》、《Hadoop大数据技术基础与应用》。
持续分享有用、有价值、精选的优质大数据面试题致力于打造全网最全的大数据面试专题题库

90%大数据面试中会被问到的10道必考面试大题
持续分享有用、有价值、精选的优质大数据面试题致力于打造全网最全的大数据面试专题题库

大数据面试题总结一波,助力准备在年底跳槽寻找好工作的小伙伴们,只有度过笔试这一关才能在下面的关卡中大展宏图!Hadoop,Spark,Flink,数据仓库,10多个技术面、100多道面试题,为你的面试保驾护航。

大数据9大实战项目,解决你写论文、找工作的难题。项目资料包:项目工具、安装包、配置文件、工程源码、数据集、PPT、操作文档。
作 用Hadoop 是用在商业主机网络集群上的大规模、分布式的数据存储和处理基础架构。监控和管理如此复杂的分布式系统是不简单的。为了管理这种复杂性,Apache Ambari 从集群节点和服务收集了大量的信息,并把它们表现为容易使用的,集中化的接口:Ambari Web功 能显示诸如服务特定的摘要、图表以及警报信息创建和管理 HDP 集群并执行基本的操作任务,例如启动和停止服务,向集群中添加主机,
导读:本文的主题是网易大数据HDFS的优化和实践,下面会从三个方面来介绍网易在大数据存储相关的工作和努力。网易大数据平台HDFS在网易的实践及挑战重点业务分享01 网易大数据平台网易引入Hadoop十年有余。开源是大数据行业的发展趋势,网易也是本着开源开放的心态来做好大数据。近年来随着业务的发展,网易实现了大数据跨云部署,跨云生产,为业务在生产效益上带来了很多益处。上图是网易大数据平台的示意图,从
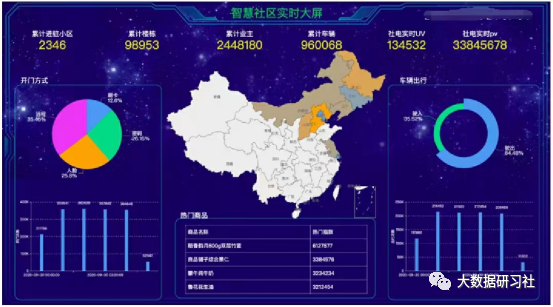
中国“城镇化”的背景下,为了积极响应政府提出的城市化发展策略,把“智慧城市”作为业务发展重点,确立了“共建 汇聚 共享”为发展模式的智慧城市发展战略。