




- @cufewxy1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文简要介绍BP神经网络(BPNN, Back Propagation Neural Network)的思想。BP神经网络是最基础的神经网络,结果采用前向传播,误差反向(Back Propagation)传播方式进行。BP神经网络是有监督学习,不妨想象这么一个应用场景:输入数据是很多银行用户的年龄、职业、收入等,输出数据是该用户借钱后是否还贷。作为银行风控部门的负责人,你希望建立一个神经网络模型,
请注意,计算y对x的梯度时,如果y、x都是矩阵,梯度理应是每一个y对每一个x求偏导的结果。但在Tensorflow中,gradient是返回了总和的梯度。如果想求出每个分量的梯度,应该使用Jacobian矩阵。这一点困扰了笔者很久,直到翻到文档才恍然大悟。

反卷积(deconvolution)又称转置卷积,是卷积的拟操作,常用于GAN等模型中。反卷积是上采样的一种,上采样是指将特征图维度恢复到原始图的维度,这种增大维度的过程被称为上采样。上采样可以用插值或反卷积实现。在CNN中,卷积一般会让图像尺寸变小,属于下采样。例如最大化池化(可视为特殊的卷积)是将相邻像素中最大的像素提取出来,丢弃了其他不重要的像素。卷积和反卷积是相反的过程。GAN等生成模型中

知识蒸馏(Knowledge Distillation)是深度学习领域很火的概念,是一种模型压缩、知识迁移的技术。它从一个参数多、结构复杂、维护成本高的大模型(称为教师模型)迁移到参数少、结构简单、维护成本低的小模型(称为学生模型)。迁移的原因很简单,复杂的大模型虽然能够取得很好的效果,但是参数量过大,推理成本高,计算量过大,需要的硬件资源多,很难在资源小的硬件上运行(尤其是移动设备)。知识蒸馏通

卷积是一种数学运算,记为f,g的卷积连续的定义为离散的定义为从定义式中可发现卷积的要点:(1)卷积的入参为n;(2)2个函数遍历所有可能的入参,求乘积后求和;(3)在此过程中保证2个函数的入参之和为n。单纯看计算公式不算复杂,但让人疑惑为什么设计成这种形式?下面我们举一些例子加深理解。
笔者工作中需要使用多种信创数据库,在使用过程中发现一些问题,现记录如下。

卷积核是3*3的形式,输入图像是4*4的形式,步长为1,则可以将卷积操作转换为矩阵操作,其中卷积核转变成了一个4*16的稀疏矩阵(稀疏是指其中很多元素是0),将输入图像展开成一列形式16*1,得到输出图像reshape成4*1的形式。卷积和反卷积里都有stride和padding参数,但是同一个参数在卷积和反卷积里的作用不一样,非常容易使人困惑,本文试图理清他们的关系,并用实际数值例子演示计算过程

请注意,计算y对x的梯度时,如果y、x都是矩阵,梯度理应是每一个y对每一个x求偏导的结果。但在Tensorflow中,gradient是返回了总和的梯度。如果想求出每个分量的梯度,应该使用Jacobian矩阵。这一点困扰了笔者很久,直到翻到文档才恍然大悟。
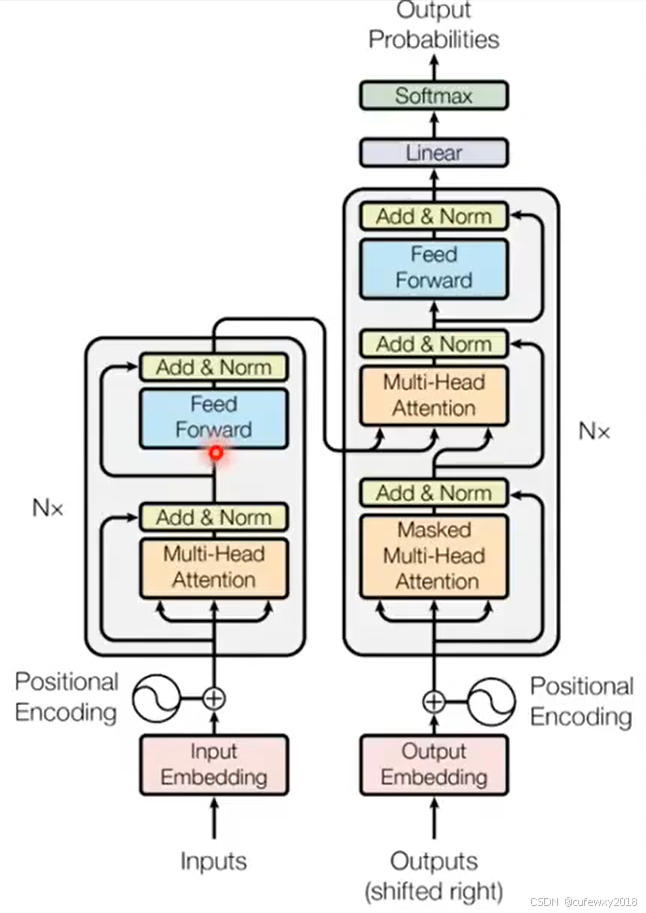
Token是语言模型中常见的概念,中文可称为“词元”,是文本处理的基本单元。第一,方便识别词与词之间的相对位置关系,因为第i个词与第i+k个词之间是有规律的,基于正弦和余弦定理,sin(i+k)=sin(i)cos(k)+cos(i)sin(k), cos(i+k)=cos(i)cos(k)-sin(i)sin(k),因此,两个前后间隔k个位置的编码是有线性规律的,这就像是编码阶段预留的“彩蛋”,
Logistic回归(逻辑回归)是基础的分类模型,将输出限定在0-1之间,表示分类的概率。在分类时,可设定阈值为0.5,概率超过0.5表示正例,小于0.5表示负例。应用场景包括医学检测(是否患病,肿瘤良性恶性)、金融(信用卡违约)、市场营销(客户是否流失)等。
