- @cskywit
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
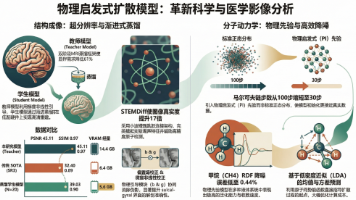
物理驱动扩散模型在科学计算与医学影像中的创新应用 摘要:物理驱动扩散模型通过将物理定律(如PDE方程、统计力学先验)嵌入生成式深度学习架构,解决了纯数据驱动模型在科学计算中的关键挑战。在计算流体动力学领域,这类模型利用PDE残差梯度实现了高保真湍流场重构;在医学MRI中,通过整合Bloch方程和k空间热扩散原理,显著提升了欠采样重建精度。研究还展示了该技术在显微图像生成、分子模拟优化等领域的突破性
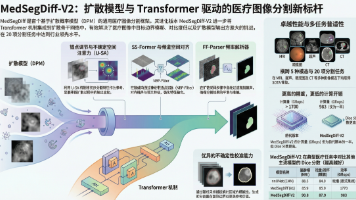
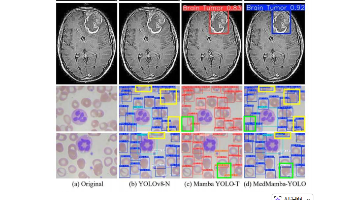
本文系统分析了两代基于扩散模型的医学图像分割方法:MedSegDiff和MedSegDiff-V2。MedSegDiff首次将去噪扩散概率模型(DPM)应用于医学图像分割,通过动态条件编码和FF-Parser模块解决了病灶边界模糊问题。MedSegDiff-V2则创新性地将Transformer与扩散模型结合,提出锚点条件和频谱空间Transformer架构,在20项任务中刷新性能记录,同时显著提
斯坦福大学计算机类课程都是以CS开头编号,可以在网址https://exploredegrees.stanford.edu/coursedescriptions/cs/查询,在网上可以登录查看课程的课件和视频等,在B站上可以搜索到部分带中文字幕的授课视频,名校的视频确实非常板扎。B站:https://search.bilibili.com/all?keyword=%E6%96%AF%E5%9D%A
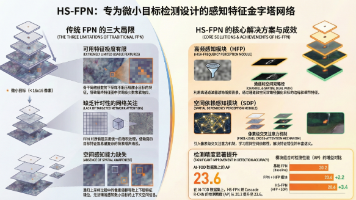
本文提出了一种名为HS-FPN的新型特征金字塔网络,用于解决微小目标检测中的特征匮乏和空间感知不足问题。该网络包含两个核心模块:高频感知模块(HFP)通过离散余弦变换滤除低频背景噪声,结合通道和空间注意力机制增强微小目标特征;空间依赖感知模块(SDP)采用跨注意力机制捕获像素级长程依赖关系。实验表明,HS-FPN能显著提升微小目标的信杂比,可作为插件模块集成到主流检测器中。作者还提供了关键模块的P
本文系统地梳理了从2016年诞生到2026年预见性的十年演进历程。文章核心聚焦于从传统的“分治法”向的哲学转变,详细解析了各代版本如何通过优化主干网络、引入及后续转向,在检测精度与推理速度之间寻找动态平衡。技术演进的主线涵盖了、梯度信息保护以及最终消除与极致推理效率发展的未来工业趋势。
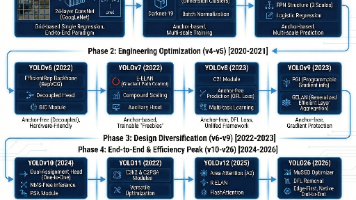
通过阅读上述代码实现,我们可以发现 MedMamba-YOLO 的改进并非盲目的模块堆砌。CPIB 的通道交叉保证了微弱特征不丢失,MSF-FPN 与 SAVSSB 通过跨尺度连接与“CNN + Mamba”的互补机制构建了强大的时空感知能力,而 HMDA 进一步实现了对尺度变化的自适应兼容。理解这套设计逻辑,对改进其他工业视觉模型同样具有极高的参考价值。
以前一直都是在Windows上玩CPU版的Tensorflow,现在有时间弄一下,买了一根16GB的内存条扩容上。以前是Win10+Ubuntu双系统,以前的Ubuntu上由于做实验有一堆的错误待解决,现在懒得折腾了,直接装成Ubuntu单系统。我的电脑配置如下:CPU:Intel Core i7-7770HQ内存:24GB显卡:NVIDIA 940MX硬盘:128GBS...
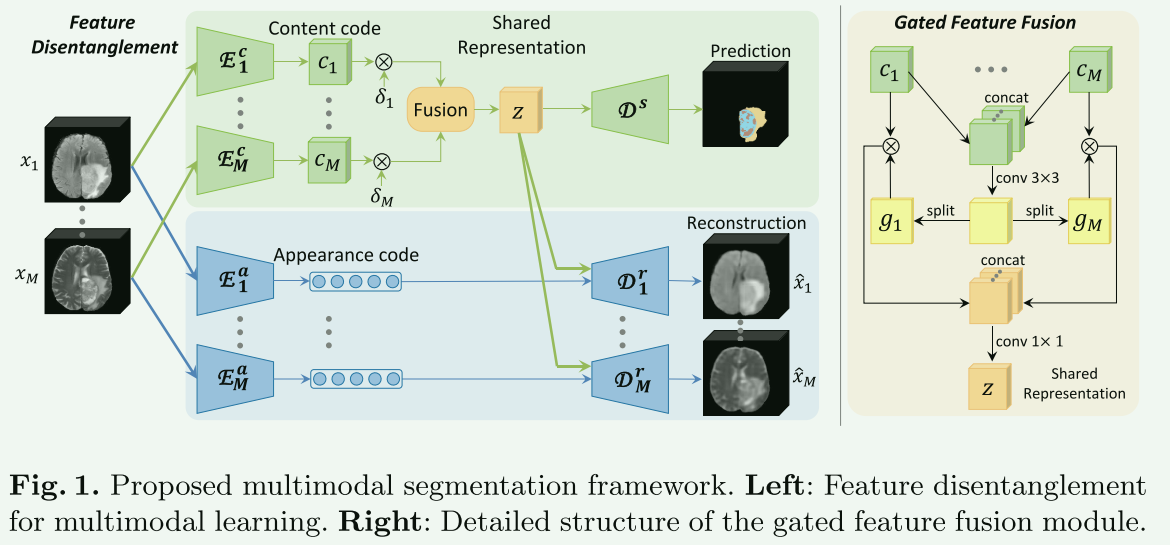
4篇应用解耦表示学习的文章,这里只关注如何解耦,更多细节不关注,简单记录一下。
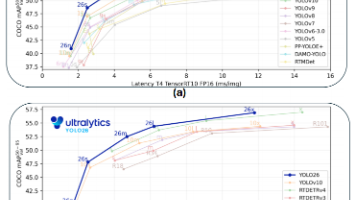
因为矩阵是 3x3,但我们只用了2条线,线数(2)< 维度(3),说明目前的 0 还不够多,还没法达成完美的一对一分配。MuSGD 利用这一迭代,在几乎不增加额外显存负担的情况下,获取了包含平滑曲率信息的正交化梯度 ,使得 YOLO26 能够以更少的训练轮数(Epochs)稳定收敛。在模型优化方面,YOLO26 提出了 MuSGD 优化器,它结合了传统 SGD(随机梯度下降)的泛化能力,并吸收了常
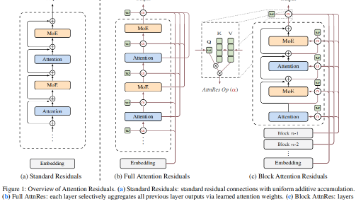
在现代大语言模型(LLM)的架构中,带有 PreNorm 的标准残差连接(Residual Connections)几乎是不可或缺的基石。然而,这一习以为常的基础结构是否存在底层的数学缺陷?2026年3月16日,Kimi 团队发布了技术报告《Attention Residuals》,直接向这一经典结构提出了挑战。该研究指出,传统的残差连接会导致深层网络出现严重的“幅值膨胀”与“信息稀释”问题。为此