- @clchyj
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Nexent定位为一个开源的零代码智能体自动生成平台。与传统的“编排”思路不同,它基于优化后的SmolAgents框架,将用户的自然语言指令作为“需求规格说明书”。当用户输入如“创建一个能够分析季度销售报表、自动总结核心指标并生成可视化建议的数据分析师助手”这样的描述时,Nexent的后台引擎会执行一系列自动化操作:理解任务场景、定义智能体角色与目标、自动生成结构化的系统提示词、并匹配合适的工具(
开源神器LocalAI彻底开源替代OpenAI,隐私无忧、离线运行,普通人也能玩转大模型!小伙伴们,还在为使用在线AI服务的隐私担忧和费用发愁吗?今天给大家安利一个颠覆性的开源项目——LocalAI!它让你能在自己的电脑上完全本地化部署各类大语言模型、图像与音频生成AI,彻底告别网络依赖和隐私泄露风险。最惊喜的是,它无需昂贵GPU,普通电脑也能流畅运行,并完美兼容OpenAI API,现有应用无缝
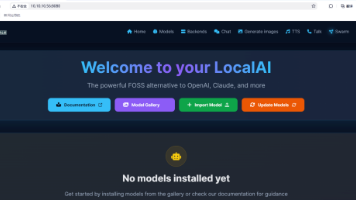
开源神器LocalAI彻底开源替代OpenAI,隐私无忧、离线运行,普通人也能玩转大模型!小伙伴们,还在为使用在线AI服务的隐私担忧和费用发愁吗?今天给大家安利一个颠覆性的开源项目——LocalAI!它让你能在自己的电脑上完全本地化部署各类大语言模型、图像与音频生成AI,彻底告别网络依赖和隐私泄露风险。最惊喜的是,它无需昂贵GPU,普通电脑也能流畅运行,并完美兼容OpenAI API,现有应用无缝
Nexent定位为一个开源的零代码智能体自动生成平台。与传统的“编排”思路不同,它基于优化后的SmolAgents框架,将用户的自然语言指令作为“需求规格说明书”。当用户输入如“创建一个能够分析季度销售报表、自动总结核心指标并生成可视化建议的数据分析师助手”这样的描述时,Nexent的后台引擎会执行一系列自动化操作:理解任务场景、定义智能体角色与目标、自动生成结构化的系统提示词、并匹配合适的工具(
在当今AI应用蓬勃发展的浪潮中,我们似乎已经习惯了这样的模式:一个绝妙的想法诞生,然后我们转向如Vercel v0、Lovable或Bolt这样的云端平台,用自然语言描述它,等待云端服务器生成代码和应用。然而,这个过程伴随着数据隐私的担忧、API调用成本的累积以及潜在的供应商锁定风险。Dyad正是对这一主流模式的本地化、开源化回应。它是一个免费、开源的AI应用构建平台,其核心理念是“本地优先”。与
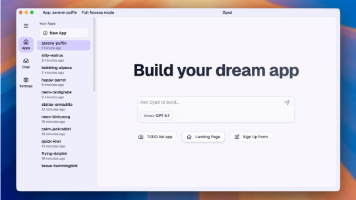
在当今AI应用蓬勃发展的浪潮中,我们似乎已经习惯了这样的模式:一个绝妙的想法诞生,然后我们转向如Vercel v0、Lovable或Bolt这样的云端平台,用自然语言描述它,等待云端服务器生成代码和应用。然而,这个过程伴随着数据隐私的担忧、API调用成本的累积以及潜在的供应商锁定风险。Dyad正是对这一主流模式的本地化、开源化回应。它是一个免费、开源的AI应用构建平台,其核心理念是“本地优先”。与
如果说Linux是操作系统的基石,那么无疑是计算机视觉领域的同等存在。自2000年由英特尔研究院发起以来,这个开源库已走过二十余年历程,成长为全球计算机视觉研究者和开发者首选的“瑞士军刀”。作为一个基于BSD许可发行的跨平台库,OpenCV汇聚了数千名全球开发者的智慧。其GitHub仓库拥有超过85.6万星标,这一数字直观印证了它在业界无可撼动的地位。为计算机视觉应用提供一套通用、高效的基础设施,
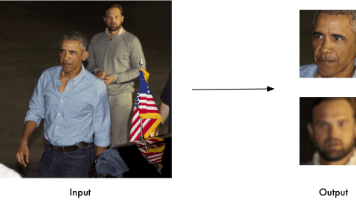
小伙伴们,今天给大家推荐一款开源AI神器,能够自动打通后端,将用户信息,业务数据直接保存到数据库中。AI工具,名字叫做:AipexBase,它是完全开源的。在AI生成代码过程中,我们不需要搭建数据库,不需要手动建表,也不需要手动插入数据,这些事情全部由AipexBase自动完成并对接到数据库。

当对话长度超过设定阈值时,系统会自动将较早的对话内容总结成简短摘要,既保留了关键上下文信息,又节省了宝贵的Token消耗,从而支持超长对话。