




- @choose_c
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MoriFlow提出MiroThinker v1.0开源研究代理框架,通过增强交互能力而非单纯扩大模型规模来提升性能。该框架支持256K上下文窗口和600次工具调用,采用强化学习优化决策,结合近时上下文管理策略。研究发现交互扩展能有效纠正推理错误,但存在工具冗余使用、思维链过长及多语言混合等局限。实验表明交互深度是提升研究代理能力的第三维度,为智能体发展提供了新方向。相关工作包括代理基础模型和深度
github:https://github.com/MaartenGr/KeyBERTguides:https://maartengr.github.io/KeyBERT/guides/quickstart.html使用向量计算抽取关键词,只需要预训练模型,不需要额外模型训练。流程:1.没有提供分词功能,英文是空格分词,中文输入需要分完词输入。2.选择候选词:默认使用CountVectorizer
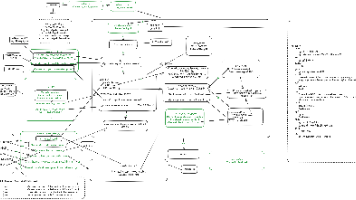
这篇博客介绍了一个名为“open-canvas”的开源项目,该项目由langchain.ai推出,旨在与ChatGPT合作进行写作和编程。博客详细描述了项目的实现逻辑,包括使用langgraph的流程图,说明了生成和修改内容(artifact)的各个节点及其输入输出关系。主要功能包括高亮选择、主题按钮的选择(针对代码和文本的不同主题),以及输入查询的处理。最后,博客提到用户风格和写作风格的反思过程
由于在做一些语义相似的工作,其中看了陈丹奇组的SimCSE使用了对比学习刷新了有监督和无监督的SOTA,自己也在做一些相关的下游任务的实验,其中就使用了图像和nlp都非常火的对比学习的方法,看了一下张俊林大神知乎对于对比学习的研究进展精要,讲的还是一如既往的清晰易懂。还是做一下搬运工,做一下自己的提炼记录。对比学习分类对比学习是无监督学习中自监督学习中的一种,其中NLP中的预训练模型MLM就是自监
原文地址:https://pan.baidu.com/s/1LNolV-_SZcEhV0vz2RkDRQ;本文进行翻译和总结。VAEVAE是两种主要神经网络生成模型中的一种,另一种典型的方法是GAN。VAE是一种自编码器,在训练时将数据编码成正则化的隐层分布,该隐层分布可以生成新的数据。其中,"变分"一词来自正则化和统计学中变分推断的关系。本文想要解决的问题:1.什么是自...
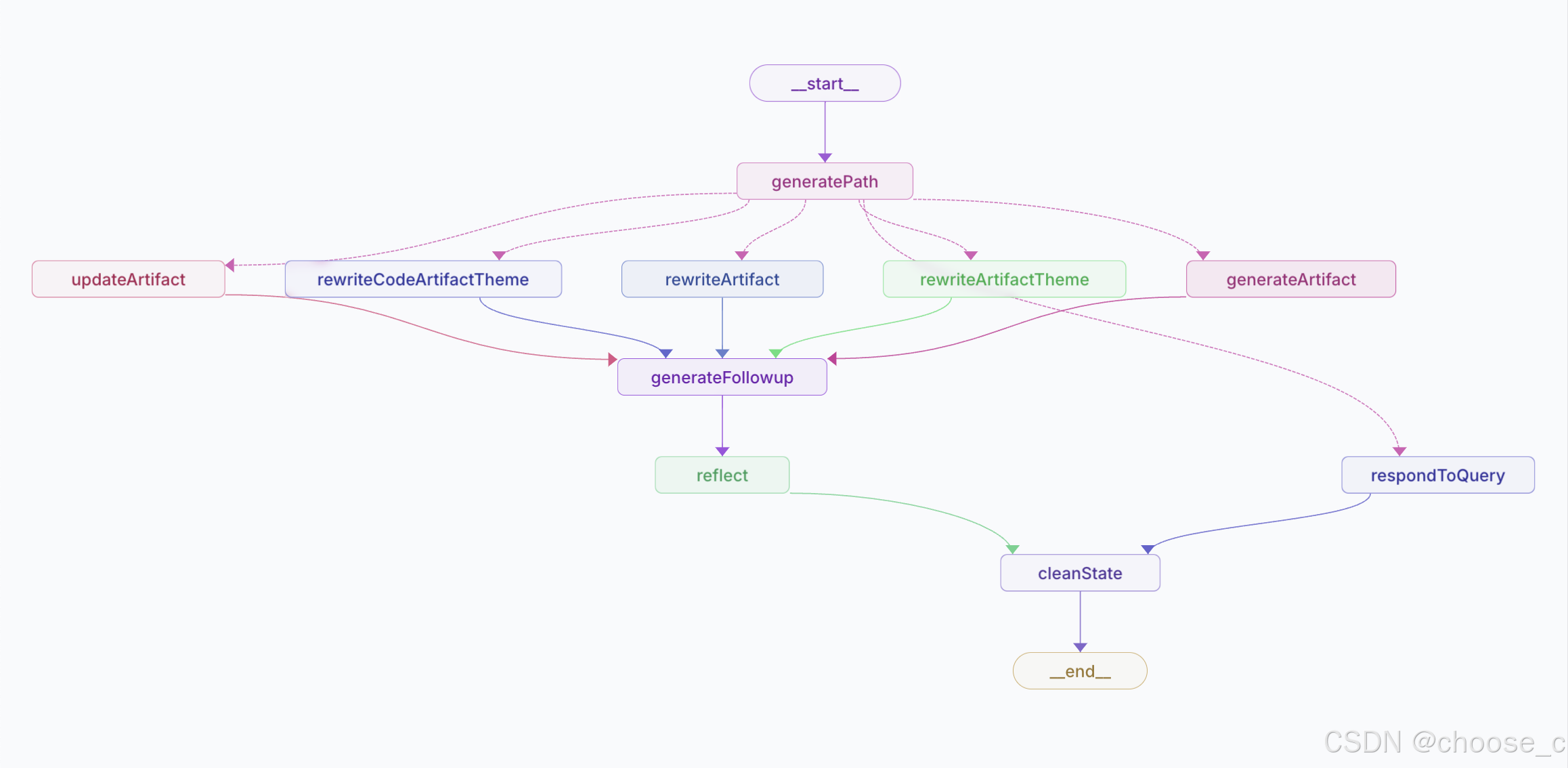
大模型背景下,两种不依赖大模型和prompt构建框架的的few shot文本分类方法,setfit和fastfit能够高效地实现少镜头下的文本分类任务。
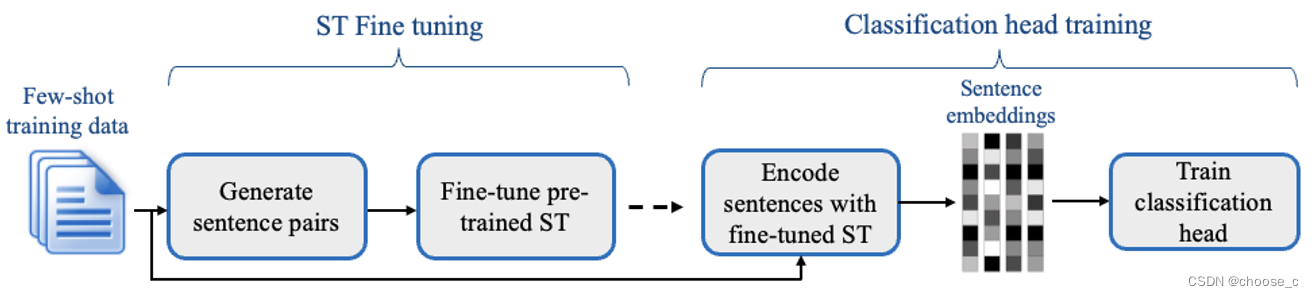
检索增强语言模型可以更好的融入长尾问题,但是现有的方法只检索短的连续块,限制了整个文档上下文的整体理解。文本提出方法:递归对文本块进行向量化,聚类,摘要,从下到上构建一棵具有不同摘要级别的树。要解决的问题是,大多数现有的方法只检索几个短的、连续的文本块,这限制了它们表示和利用大规模话语结构的能力。这与需要整合文本多个部分知识的主题问题特别相关,前k个检索到的短连续文本将不包含足够的上下文来回答问题
原文地址:https://pan.baidu.com/s/1LNolV-_SZcEhV0vz2RkDRQ;本文进行翻译和总结。VAEVAE是两种主要神经网络生成模型中的一种,另一种典型的方法是GAN。VAE是一种自编码器,在训练时将数据编码成正则化的隐层分布,该隐层分布可以生成新的数据。其中,"变分"一词来自正则化和统计学中变分推断的关系。本文想要解决的问题:1.什么是自...