




- @chinawangfei
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今天遇到一个奇怪的事情,curl无法访问http/https url地址,但是postman可以调用,浏览器也可以访问。如下所示:仔细看了下curl -v的返回值,发现请求的是本地IP和端口,推测可能有http代理进程干扰。于是,顺藤摸瓜,查询下是否有进程占用这个端口,使用命令如下:$ netstat -a | grep 8123结果如下所示:确实是有进程占用这个端口,使...
本人在IDEA中导入一个名称为CUT的项目后,打开 File——>Project Structure...,点击左侧的Modules,发现除了名称为CU的module,还有一个“main”和一个“test”。通过查看详细信息,发现“main”和“test”都属于“CUT”这个项目。 在这样的情况下,执行add JARS or directories或者add Libra...
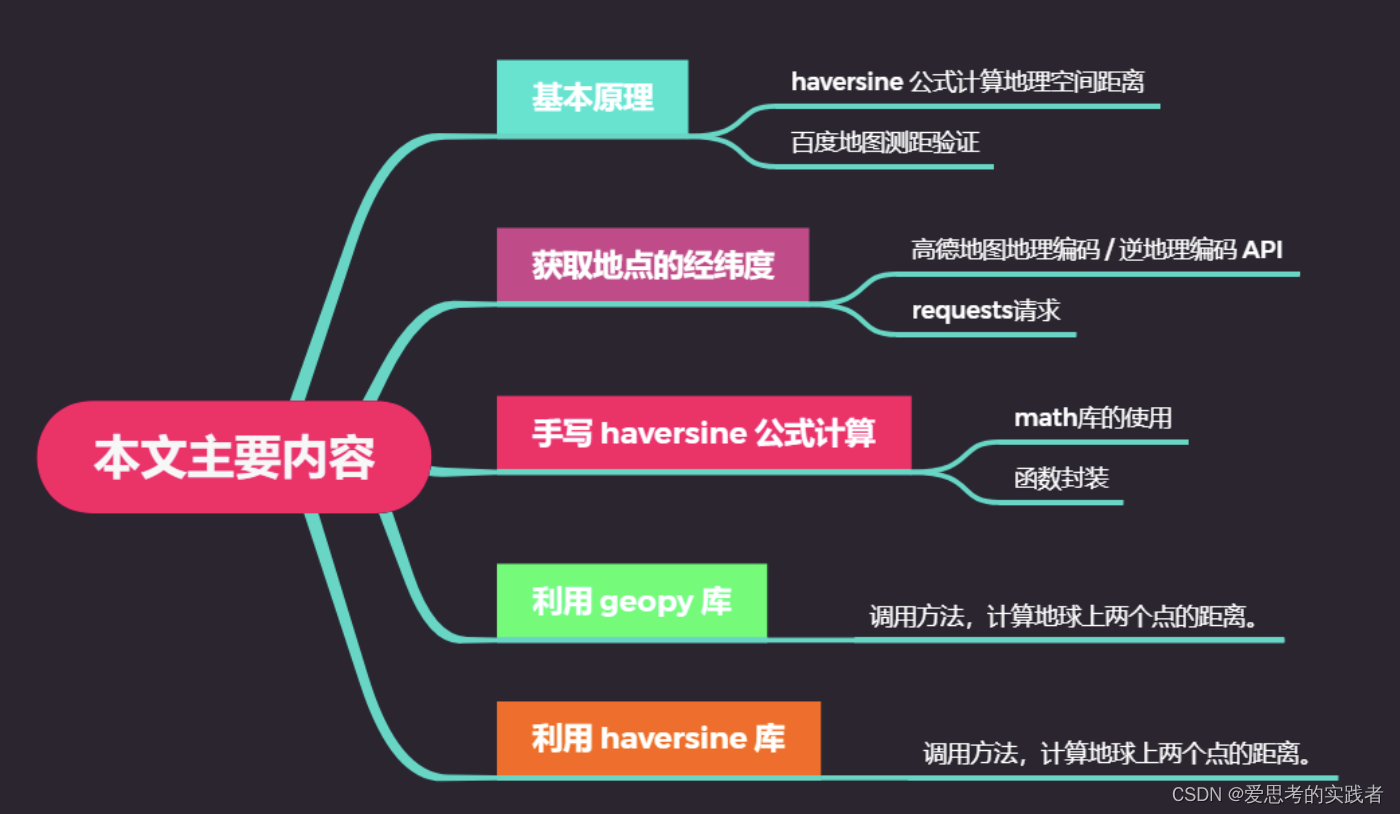
处理地理数据时,经常需要用到两个地理位置间的距离。以点(经度值,纬度值)表示地点的经纬度坐标,比如 A 点经纬度(30.553949,114.357399),B点经纬度(129.1344,25.5465),求 AB 两点之间的距离。已知地球上任意两点(lng1,lat1),(lng2, lat2)的经纬度坐标,本文讲解如何求两点间的距离。...
一、PyCryptodome说明PyCryptodome是python一个强大的加密算法库,可以实现常见的单向加密、对称加密、非对称加密、非对称加密算法签名和流加密算法。直接pip安装即可:pip install pycryptodome官网地址:https://pypi.org/project/pycryptodome/二、base64编码2.1 base64编码说明原理:将要编码的内容按3字节
一、完全背包问题描述有5种物品和1个背包,每种物品的个数是无限的,背包最多只能装下10公斤的物品。怎样选择物品,使得背包能装下并且得到的价值最大。物品的重量、价值如下所示:物品编号重量价值126223365454546二、解题思路我们先看下多重背包实现原理:背包问题之多重背包_爱思考的实践者的博客-CSDN博客对比分析发现,完全背包与多重背包的差别就是:对物品
处理地理数据时,经常需要用到两个地理位置间的距离。以点(经度值,纬度值)表示地点的经纬度坐标,比如 A 点经纬度(30.553949,114.357399),B点经纬度(129.1344,25.5465),求 AB 两点之间的距离。已知地球上任意两点(lng1,lat1),(lng2, lat2)的经纬度坐标,本文讲解如何求两点间的距离。...
/* 在hmp DB服务器上执行一下sql *//* modify table [hmp_data_glucose_XXX] structure */USE bwfHmp;DROP PROCEDURE IF EXISTS bwfHmp.addColumns;CREATE PROCEDURE bwfHmp.addColumns(IN _tabName VARCHAR(30),IN
celery介绍、架构、基本使用,celery执行异步任务、延迟任务、定时任务,django中使用celery。
一、Quartz中设置cron时间表达式Quartz中设置cron时间表达式的格式为: <!-- s m h d m w(?) y(?) -->, 分别对应: 秒、分、小时、日、月、周、年。1.每天什么时候执行每天23:59:00开始执行,cron表达式为:0 59 23 * * ?每天11:01,11:02,11:03; 12:01,12:02,12:03分执行任务,cron表达式为
所谓c10k问题,指的是:服务器如何支持10k个并发连接,也就是concurrent 10000 connection(这也是c10k这个名字的由来)。由于硬件成本的大幅度降低和硬件技术的进步,如果一台服务器能够同时服务更多的客户端,那么也就意味着服务每一个客户端的成本大幅度降低。从这个角度来看,c10k问题显得非常有意义。一、C10K问题由来互联网的基础是网络通信,早期的互联网可以说是一...