




- @ccsss22
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: FPGA凭借可定制架构和低延迟优势,成为边缘端AI加速的优选方案。本文提供从零搭建FPGA AI加速流程的实战指南: 环境搭建:强调工具链兼容性(如Vivado/Vitis AI)与Linux环境配置; 核心概念:解析并行计算与流水线设计,以空间换时间提升吞吐量; 模型部署:从ONNX导出、INT8量化到编译优化,生成可烧录的比特流; 资源优化:混合精度量化、数据复用与循环展开技巧; 调试
智能自主运动体技术综述 摘要:智能自主运动体是一种集环境感知、决策规划与运动控制于一体的智能系统,能够独立完成复杂环境下的自主运动任务。其核心技术包括:1)多传感器数据融合,通过激光雷达、视觉传感器等构建环境三维模型;2)SLAM定位与建图技术,基于扩展卡尔曼滤波实现实时定位与地图构建;3)路径规划算法,采用A*、RRT等算法结合强化学习进行最优路径决策;4)高精度运动控制,运用PID和模型预测控
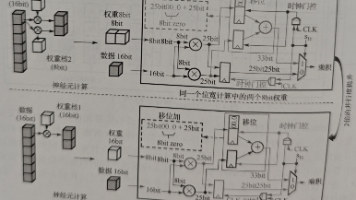
《位宽自适应MAC技术设计与实现》 摘要:本文提出了一种位宽自适应MAC(乘累加)技术,通过动态配置8bit/16bit运算模式,显著提升了硬件计算效率。该设计采用灵活的硬件架构,支持并行乘法运算(8bit模式)和组合乘法运算(16bit模式),通过s11控制信号实现位宽动态切换。Verilog实现验证表明,该技术具有三大优势:1)通过模式切换提升计算效率;2)根据精度需求降低动态功耗;3)优化硬
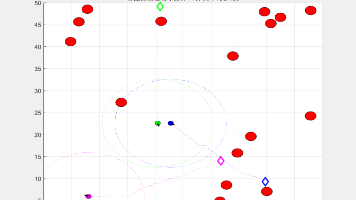
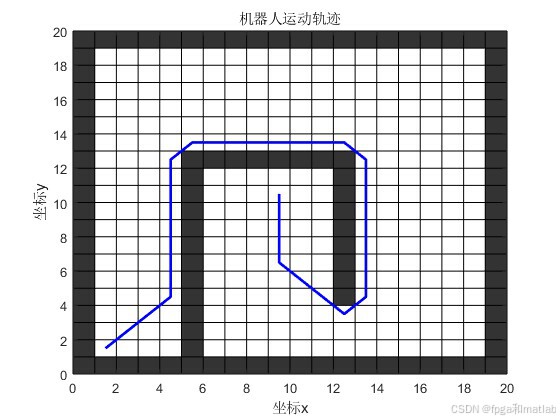
蚁群优化算法(Ant Colony Optimization, ACO)是一种启发式优化技术,灵感来源于自然界中蚂蚁寻找食物时的集体行为。在机器人路径规划领域,ACO通过模拟蚂蚁在环境中留下信息素并据此探索路径的过程,为机器人寻找从起点到终点的最优路径提供了有效的解决方案。
1.问题描述:复杂背景下目标检测存在诸多困难,主要为背景对目标检测的干扰,大量噪声存在导致传统导数边缘检测方法的失效等。本文正是针对上述两点,提出了分割区域图像、利用形态学方法检测目标的新算法;即首先利用目标与背景灰度差异性来确定目标的大致区域,将其分割出来,然后再结合多结构元素法进行目标的精确检测。通过与原图像分割、聚类算法分割实验比较,该算法在文中的应用实例中表现出了较好的抗干扰性和抗噪性能。
摘要:CsiNet-LSTM是一种融合空间特征压缩与时间序列处理的动态信道状态反馈模型。该模型通过编码器(3层CNN+全连接层)压缩CSI空间特征,利用LSTM捕获历史信道的时间相关性,解码器结合时空信息重构CSI。Matlab实现采用归一化数据训练,以NMSE评估重构精度。实验表明,该模型在MIMO系统中能有效降低反馈开销并保持高重构精度,适用于动态无线信道环境。关键参数包括128位压缩向量和6
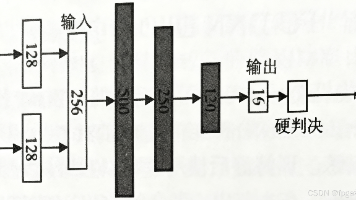
摘要:本文提出了一种基于全连接深度神经网络(FC-DNN)的OFDM接收机架构,直接实现从接收时域信号到原始比特的端到端映射。该方法通过数据驱动方式,利用大量仿真数据训练DNN网络自主学习信道失真和噪声到原始比特的映射关系,避免了传统接收机中信道估计、均衡等模块的误差累积问题。系统采用5层全连接网络结构,通过最小化比特误差进行训练。MATLAB仿真结果表明,该架构在复杂信道环境下相比传统接收机具有
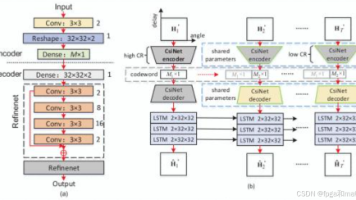
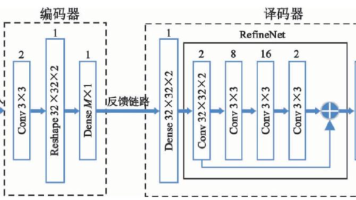
摘要:CsiNet是一种基于深度学习的CSI重建网络模型,通过卷积神经网络实现高效信道状态信息压缩与重建。该模型包含编码器和译码器两部分,编码器采用3×3卷积核处理复数信道矩阵,译码器通过全连接层和RefineNet单元重建信道。RefineNet单元采用残差连接结构,包含4层CNN网络用于优化重建质量。实验表明,CsiNet在32×32大规模MIMO系统中仅需256维码字即可实现有效重建,训练采
mnist (手写字符识别) 的数据集下载地:http://yann.lecun.com/exdb/mnist/MNIST是在机器学习领域中的一个经典问题。该问题解决的是把28x28像素的灰度手写数字图片识别为相应的数字,其中数字的范围从0到9.下载后得到四个文件:train-images-idx3-ubyte.gz,训练集,共 60,000 幅(28*28)的图像数据;train-labels-
Otsu's Method,也称为最大类间方差法,是图像处理领域中广泛使用的一种自动阈值选取方法,特别适用于二值化处理。该方法由日本学者 Nobuyuki Otsu 于1979年提出,主要应用于将灰度图像分割为前景和背景两个类别,目标是找到一个最佳阈值,使得两类像素的类间方差最大,从而达到良好的图像分割效果。
