- @caoli201314
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI Agent是一种具备自主决策和行动能力的人工智能系统,能够感知环境、规划任务并执行多步骤操作。与被动响应型AI不同,AI Agent能主动分解复杂目标,通过感知、规划、执行、记忆和学习模块完成全流程任务。目前已在办公助手、编程、客服等领域应用,展现出从"工具"向"伙伴"转变的潜力。尽管存在推理能力有限、稳定性不足等挑战,AI Agent正推动AI向&q

《Cursor+Claude AI编程快速上手教程》介绍了一日速成课程,重点讲解Cursor工具的四大核心功能:Agent(智能开发助手)、Plan(项目规划)、Debug(错误诊断)和Ask(快速问答)。课程包含从安装到实战的全流程,通过SpringBoot和Flask两个学生管理系统项目演示AI编程应用。教学资料包含视频教程、课件和源码(百度网盘提取码1234)。课程后续将推出高级实战内容,帮

《Cursor+Claude AI编程快速入门》课程提供AI编程工具Cursor的全面教学,涵盖安装、模型选择到实战应用。课程重点讲解Cursor内置的8种AI模型(包括Auto模式、Opus4.6、GPT-5.2等)的特点与适用场景,指导学员根据任务复杂度选择合适的模型。通过两个实战项目(Java和Python版学生信息管理系统)演示AI编程流程,帮助学员1天内掌握基础技能。课程提供视频教程、课

本课程《2027版Cursor+ClaudeAI编程1天快速上手》系统讲解AI编程工具Cursor的使用方法,包括基础操作、模型应用和实战开发。课程通过两个完整项目案例(Java和Python版学生信息管理系统)演示如何利用CursorOpus4.6快速开发全栈应用,涵盖Flask/Vue前后端搭建、数据库设计等关键环节。配套提供视频教程、课件和源码资源包(百度网盘提取码1234),帮助开发者一天
摘要:本文介绍了一个基于Python的微信小程序自习室预约管理系统,采用FastAPI+Vue3前后端分离架构。系统前端使用微信小程序实现用户预约、签到等功能,后端采用FastAPI框架开发RESTful接口,后台管理端使用Vue3+ElementPlus构建。主要功能包括自习室管理、座位预约、扫码签到等,有效解决了高校自习室资源紧张、座位利用率低等问题。系统通过JWT实现鉴权,并包含超时自动释放
《FastAPI Python Web开发快速入门教程》 本教程由Java1234_小锋老师主讲,提供2027版FastAPI无废话快速入门指南。课程涵盖FastAPI核心功能:自动API文档生成、参数校验、中间件、依赖注入、SQLAlchemy集成等,配套视频+课件+源码。 FastAPI作为现代高性能Python框架,基于Starlette和Pydantic构建,具备: 媲美NodeJS/Go

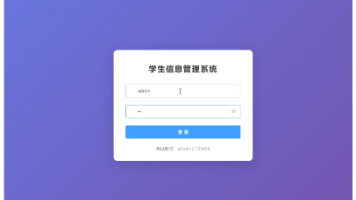
本文介绍了一个基于Python的学生选课管理系统,采用FastAPI+Vue3前后端分离架构。系统包含管理员、教师和学生三种角色,实现了课程管理、选课、退课、成绩录入等功能。后端使用FastAPI构建RESTful接口,采用SQLAlchemy ORM和JWT验证;前端使用Vue3组合式API,结合Element Plus组件库开发。系统通过严格的选课校验机制,解决了传统选课方式效率低、冲突多等问
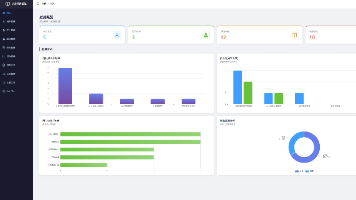
摘要:本文介绍了基于LangChain框架开发的智能客服微信小程序商城系统,采用RAG技术解决大语言模型知识滞后问题。系统包含FastAPI后端、Vue3管理后台和微信小程序前端,支持商品管理、订单处理和AI客服功能。AI客服模块通过Chroma向量数据库存储知识库,结合相似度检索增强回答准确性。测试表明系统运行稳定,有效提升客服效率和用户体验。项目源码已开放下载,为AI在电商领域的应用提供了实践
AionUi:开源AI协作桌面工具,整合多Agent统一工作流 AionUi是一款免费开源的AI协作桌面应用,支持macOS/Windows/Linux,已获2.8万GitHub Star。其核心价值在于解决用户使用多个AI工具时的痛点:需单独开启终端、系统兼容性差、操作割裂等问题。通过统一界面整合Claude Code、Codex等20+工具,支持自动检测本地CLI并通过ACP协议接入。 主要亮

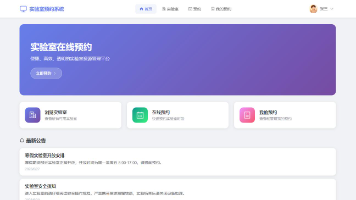
本文介绍了基于Python的实验室预约管理系统,采用FastAPI+Vue3前后端分离架构。系统解决了传统高校实验室预约方式存在的信息不透明、预约冲突等问题,实现了用户注册登录、实验室查询、在线预约、审批管理等功能。后端使用FastAPI框架,前端采用Vue3+ElementPlus组件库,具备完善的权限控制和数据校验机制。项目提供了完整的源码下载链接,并展示了核心预约管理路由代码和Vue3前端管