




- @cancer_s
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过外部获得激励来校正学习方向从而获得一种自适应的学习能力;基于人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF):构建人类反馈数据集,训练一个激励模型,模仿人类偏好对结果打分;

近几年AI产品的大火带来了新一轮的技术潮,尤为突出的是以生成式的AIGC模型。例如OpenAI公司的ChatGPT、百度的文心一言、阿里巴巴的通义千问、华为的盘古大模型等等。那么对于提示工程、RAG(检索增强)和微调,在工程当中,我们应该怎么去选择呢?首先我们需要了解大模型的流程:1.数据收集:大量的文本数据作为训练数据;2.模型搭建:构建LLM大模型3.训练模型:将收集的数据作为训练数据训练搭建

Prompt提供上下文和任务相关信息,以帮助模型更好地理解要求,并生成正确的输出;例一:问答任务中,Prompt可能包含问题或话题的描述,以帮助模型申城正确的答案;例二:在情感分析任务中,让模型做情感分类任务的做法通常是在句子前面加入前缀“该句子的情感是”即可;通过这种方式将情感分类任务转换成为一个“填空”任务,在训练过程中,BERT可以学到这个前缀与句子情感之间的关联。
通过外部获得激励来校正学习方向从而获得一种自适应的学习能力;基于人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF):构建人类反馈数据集,训练一个激励模型,模仿人类偏好对结果打分;
Prompt提供上下文和任务相关信息,以帮助模型更好地理解要求,并生成正确的输出;例一:问答任务中,Prompt可能包含问题或话题的描述,以帮助模型申城正确的答案;例二:在情感分析任务中,让模型做情感分类任务的做法通常是在句子前面加入前缀“该句子的情感是”即可;通过这种方式将情感分类任务转换成为一个“填空”任务,在训练过程中,BERT可以学到这个前缀与句子情感之间的关联。
检索增强这块主要是借鉴了RAG Fusion技术,这个技术原理比较简单,概括起来就是,当接受用户Query时,让大模型生成5-10个相似的Query,然后每个Query去匹配5-10个文本块,接着对所有返回的文本块再做个倒序融合排序,如果有需求就在加一个精排,最后取top k个文本块拼接至Prompt;它是在一个语料库上进行训练的,其中包含由Critic模型预测的检索到的段落和反思字符。因此,可以
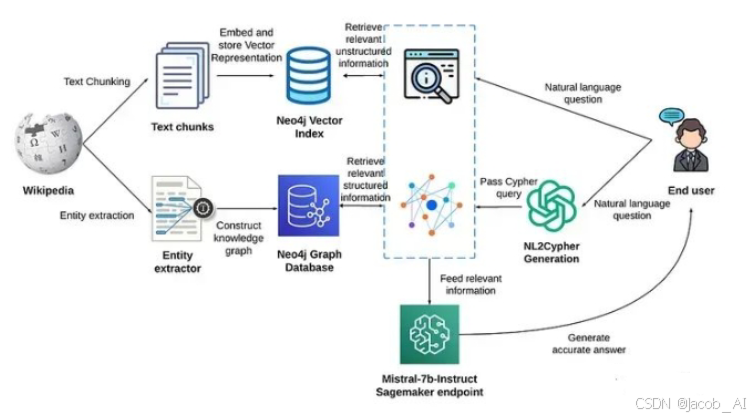
通过向量召回的方式从文档库里召回和用户问题相关的文档片段,同时输入到LLM中,增强模型回答质量。常用的方式直接用用户的问题进行文档召回。但是很多时候,用户的问题十分口语化,描述的也比较模糊,这样会影响向量的质量,进而影响模型回答的效果。
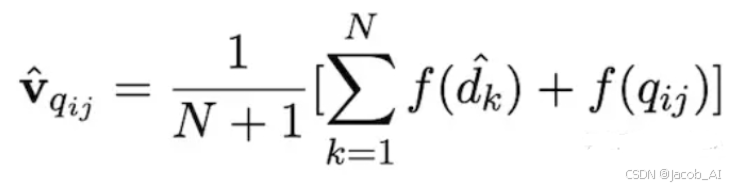
近几年AI产品的大火带来了新一轮的技术潮,尤为突出的是以生成式的AIGC模型。例如OpenAI公司的ChatGPT、百度的文心一言、阿里巴巴的通义千问、华为的盘古大模型等等。那么对于提示工程、RAG(检索增强)和微调,在工程当中,我们应该怎么去选择呢?首先我们需要了解大模型的流程:1.数据收集:大量的文本数据作为训练数据;2.模型搭建:构建LLM大模型3.训练模型:将收集的数据作为训练数据训练搭建