- @baidu_37157624
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。
技术背景本文中主要包含有三个领域的知识点:随机数的应用、量子计算模拟产生随机数与基于pytest框架的单元测试与覆盖率测试,这里先简单分别介绍一下背景知识。随机数的应用在上一篇介绍量子态模拟采样的算法中,我们就使用到了随机数,随机数在各种蒙特卡洛方法与数值计算中,扮演着非常重要的角色。在金融领域,随机数则是在加密算法中扮演重要角色,其风险在于,如果随机数可被预测,那么恶意用户就可以利用这一...
技术背景在上一篇博客中,我们用矩阵的语言介绍了量子计算中基本量子单元——量子比特,与量子门操作的相关概念。通过对量子态的各种操作,相当于传统计算机中对经典比特的操作,就可以完成一系列的运算了。但是量子计算的一个待解决的问题是,所有存储在量子态中的信息是没办法从经典世界直接读取的,只能通过量子测量,使得量子态坍缩到经典比特之后,才能够在经典世界里进行读取。量子测量的矩阵形式如果通过各种量子门...
技术背景量子计算作为一种新的计算框架,采用了以超导、离子阱等物理体系的新语言来描述我们传统中所理解的矩阵运算。不同于传统计算机中的比特(经典比特)表示方法,量子计算的基本单元被称为量子比特。我们可以通过一个布洛赫球的模型来理解二者的区别:传统比特用高电平和低电平来表示一个经典比特的1态和0态,分别对应于布洛赫球模型的南极点和北极点。这是经典比特所能够表示的信息,相当于球表面的两个点,...
接上一篇关于Docker中的Ollama养虾的文章之后,这里补充一个Docker中部署Ollama模型的方案,通过这种方式建立一个完整的虚拟化环境,确保Ollama和OpenClaw在环境内的操作都相对可控。
Ollama在本地普通算力机器上部署DeepSeek等大模型,有一定的生态优势。但是由于软件本身的一些策略问题,Windows平台的Ollama总是会随系统开机自动启动,还没有设置界面可以关闭。这里提供一种方法,可以在Windows平台永久关闭Ollama的开机自动启动功能。
本文介绍了一种在Win11操作系统下,使用Docker部署OpenClaw的一种方案,并且Token由本地部署的Ollama加载开源的qwen3.5模型产生,实现零成本、相对安全可控的一种部署方案。当然,目前OpenClaw和Ollama的安全性还是有待提升,结合自己的情况,慎重部署!!!
技术背景DeepSeek开源之后,让大家意识到了即时是在自己硬件性能一般的本地环境,也能够部署和使用大语言模型,真正实现了大模型的“私有化”。而私有化大模型之后,自然是考虑生产力的私有化。例如,如何使用大模型作为一个工具来进行编程?本文将要介绍两种不同的人工智能编程方法。Cursor的安装与使用第一种方法,是使用Cursor来进行编程,是一个跟VSCode很像的IDE,优点是支持了很多模型...
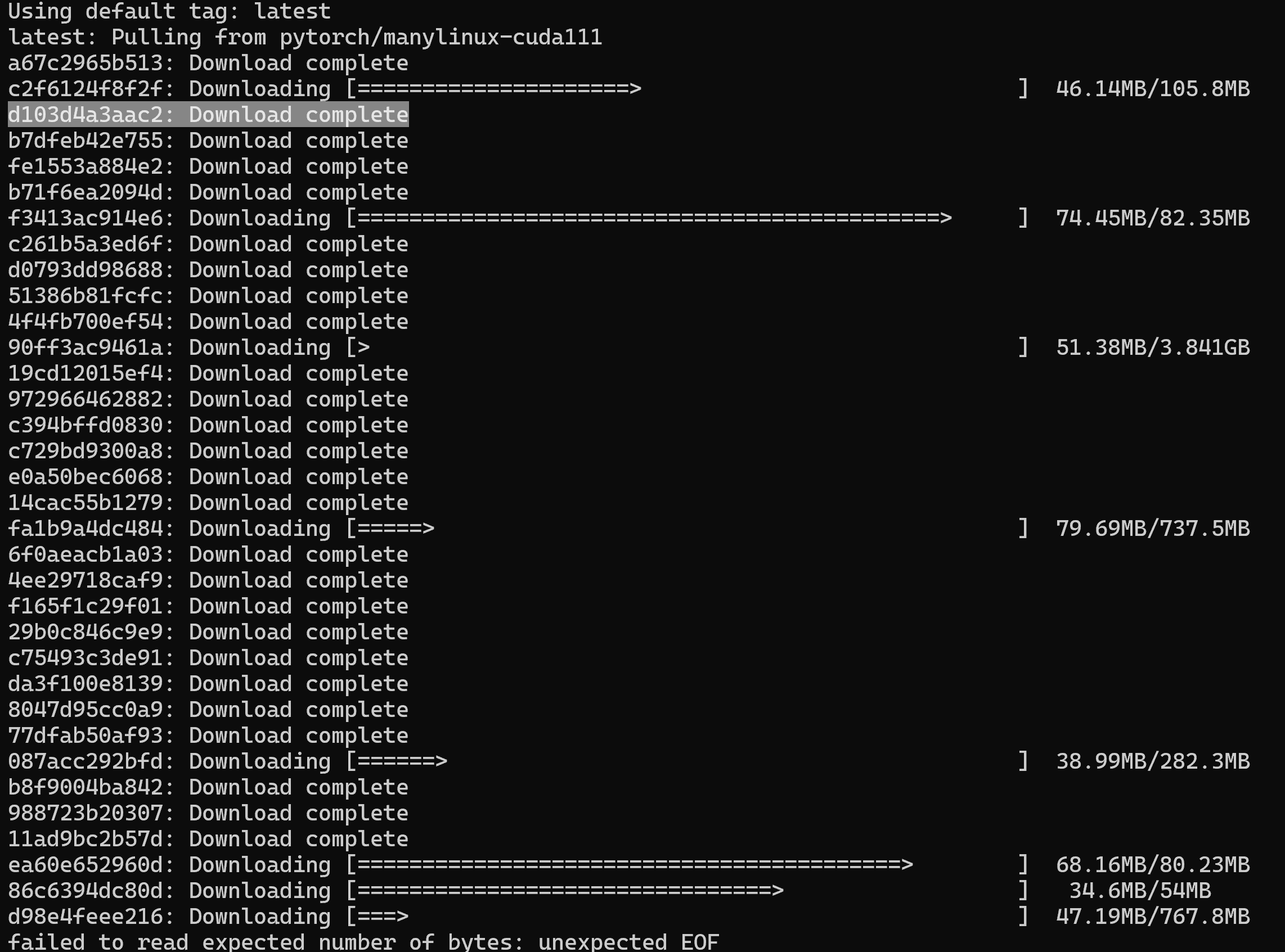
问题背景在使用Docker拉取DockerHub的镜像时,经常会出现网络不稳定的问题,这就导致拉取到一半的镜像会重新拉取,浪费时间。例如下面这种情况:第二次拉取这是一个网络中断的场景,第二次重新拉取的时候,同样是d103这个部分,又重新下载了一次。而且在不稳定的网络情况下(大概率),有可能继续中断,这就需要一个断点续传的配置。解决方案首先在docker的配置文件中加上这...
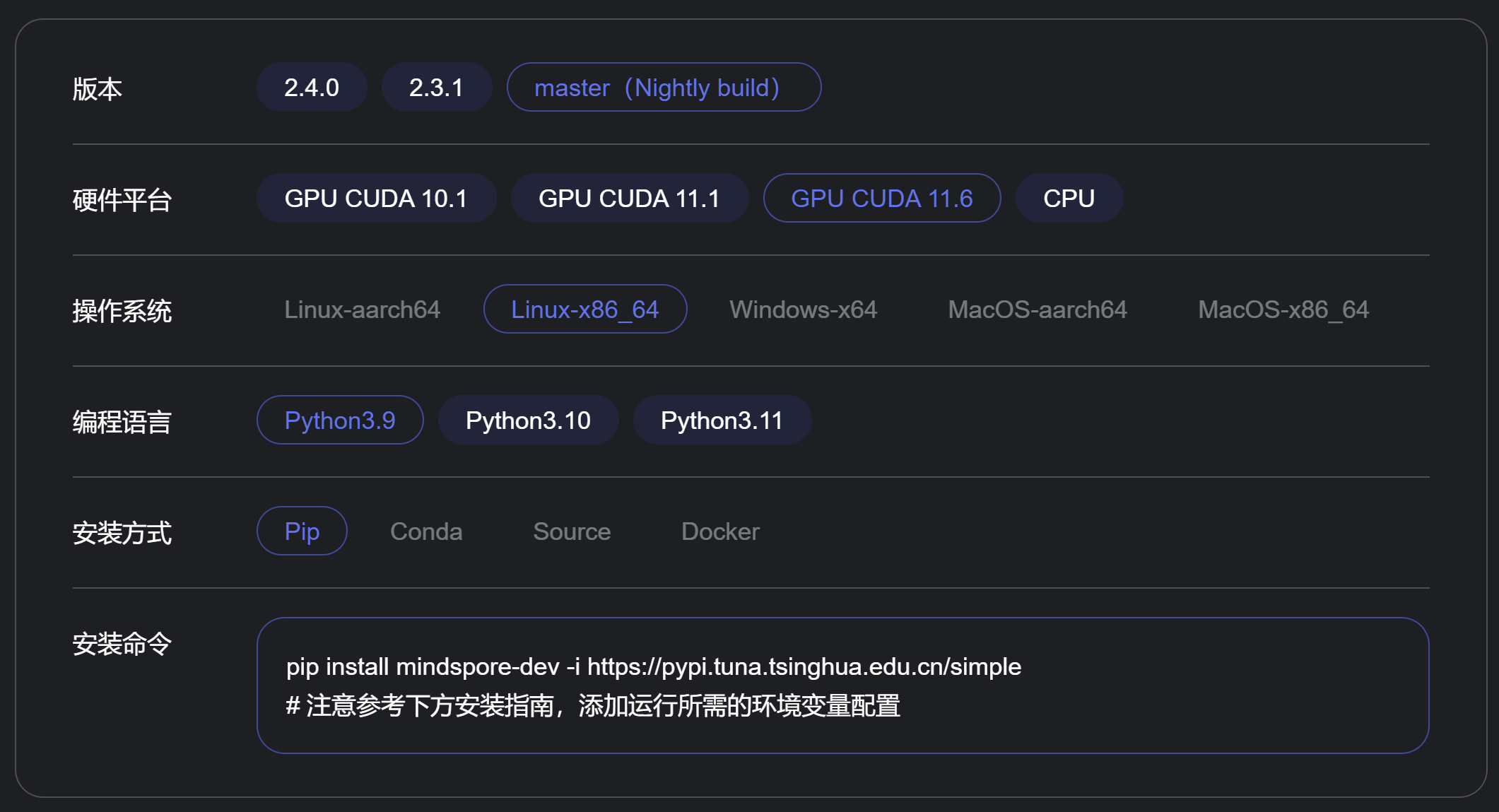
问题背景虽说在MindSpore-2.3之后的版本中不在正式的发行版中支持GPU硬件后端,但其实在开发分支版本中对GPU后端是有支持的:但是在安装的过程中可能会遇到一些问题或者报错,这里复现一下我的Ubuntu-20.04环境下的安装过程。Pip安装基本的安装流程是这样的,首先使用anaconda创建一个python-3.9的虚拟环境,因为在MindSpore-2.4版本之后不再...