




- @ahah12345678
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
公式为:v[i] = w * v[i] + c1 * rand() * (pbest[i] - x[i]) + c2 * rand() * (gbest - x[i])。更新速度 v[i] = w * v[i] + c1 * rand() * (pbest[i] - x[i]) + c2 * rand() * (gbest - x[i])更新速度 v[i] = v[i] + c1 * rand()

尽管井字游戏玩家只学习了游戏的基本动作,但没有什么能阻止强化学习在更高的水平上发挥作用,因为每个“动作”本身都可能是一种可能精心设计的解决问题的方法的应用。其次,有一个明确的目标,正确的行为需要有计划或远见,考虑到自己选择的延迟影响。强化学习解决方案的一个显著特点是,它可以在不使用对手模型的情况下,也不需要对未来状态和行动的可能序列进行明确搜索的情况下实现规划和前瞻的效果。在井字游戏的例子中,我们

如果我们让s表示贪婪移动之前的状态,s0表示移动之后的状态,那么对s的估计值的更新,表示为V(s),可以写成。例如,如果步长参数随着时间的推移适当减小,那么对于任何固定的对手,该方法都会收敛到我们的玩家在给定最佳游戏的每个状态下获胜的真实概率。换句话说,该方法收敛于玩游戏的最优策略。为了选择我们的动作,我们检查了每一个可能的动作(板上每个空格一个)会产生的状态,并在表中查找它们的当前值。我们的第二
其中隐含了从集合A(s)中采取的动作a,从集合S(在离散问题的情况下,从S+)中选取的下一个状态s0,以及从集合R中获得的回报r。请注意,在最后一个方程中,我们将两个求和合并成一个,一个是对所有s0值的求和,另一个是对所有r值的求和,合并成对所有可能值的求和。例如,如果代理遵循策略π并保持每个状态的实际回报的平均值,那么当遇到该状态次数足够多时,平均值将收敛于状态的值vπ(s)。同样,我们定义了在
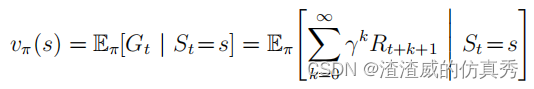
序列决策问题的经典优化方法,如动态规划,可以计算任何对手的最优解,但需要对手的完整说明作为输入,包括对手在每个棋盘状态下每次移动的概率。关于这个问题,最好的方法是首先学习对手行为的模型,达到一定的置信度,然后应用动态规划来计算给定近似对手模型的最优解。因为一个技术娴熟的球员可以打得永远不会输,所以让我们假设我们面对的是一个不完美的球员,一个有时不正确的球员,让我们获胜。状态A的值高于状态B,或者被
图神经网络(Graph Neural Network,GNN)是一种专门用于处理图结构数据的深度学习方法。与传统的神经网络主要处理规则结构的数据(如图像和文本)不同,GNN能够处理各种不规则的数据结构,如社交网络、分子结构等。GNN通过在图上定义节点之间的连接关系,利用节点的邻居信息来更新节点的表示,实现对整个图的信息传递和学习。以下是关于GNN的详细介绍,包括其原理、处理流程、主要应用方向,以及

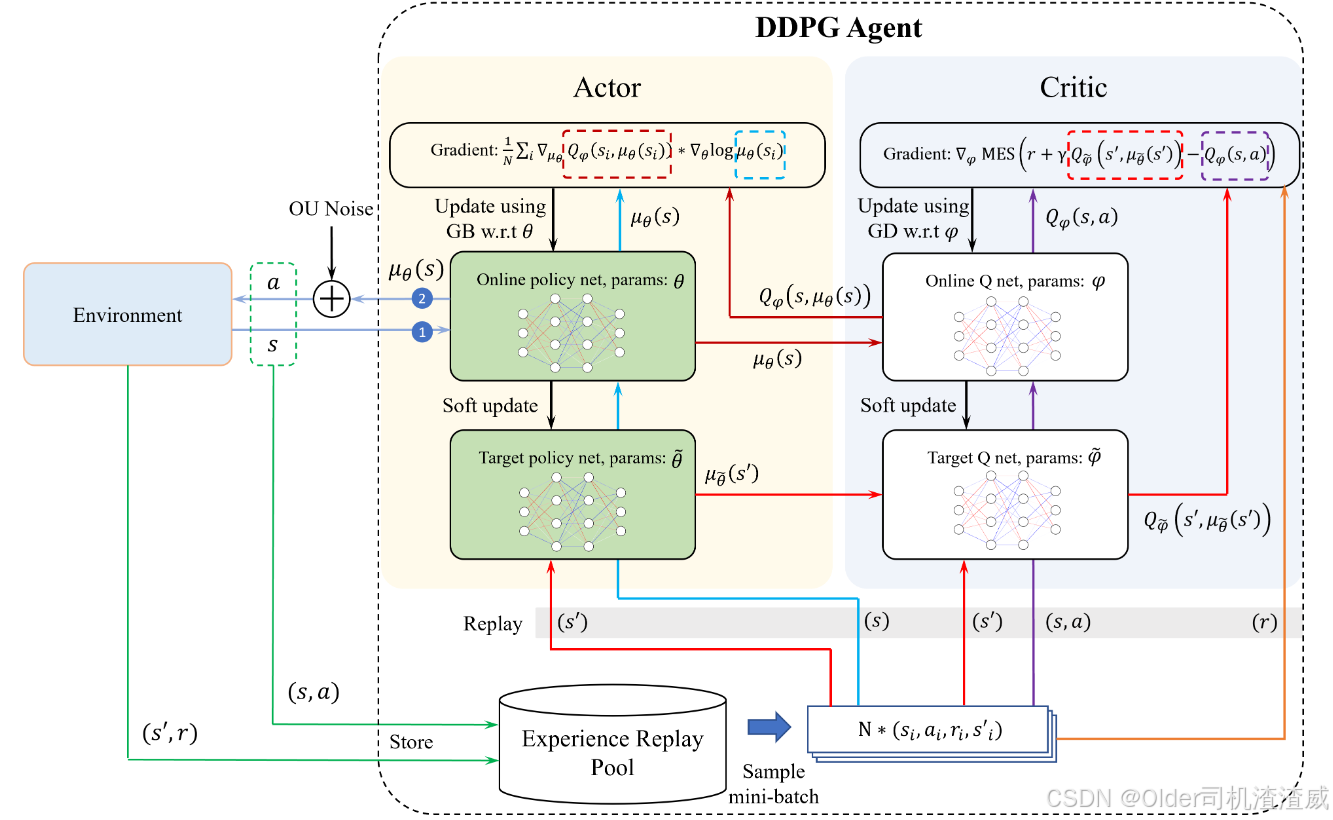
DDPG结合了策略梯度方法(Policy Gradient)和值函数方法(Value Function),使用深度神经网络(Deep Neural Networks, DNN)来近似策略函数和值函数。在DDPG算法中,有两个主要的神经网络:Actor(策略网络)和Critic(值网络)。Actor网络用于生成当前状态下的动作,Critic网络用于估计当前状态和动作对应的动作值。Critic网络的更
可以根据实际需求修改生成多项式(如果使用的不是 CRC-16 或者是自定义的多项式)以及待校验的数据内容,来实现相应的 CRC 校验功能。如果需要进行 CRC 校验验证(比如发送端计算校验码附在数据后发送,接收端校验数据是否正确),在接收端按照同样的方式重新计算接收到的数据(含原始数据和发送端发来的校验码部分)的 CRC 校验码,若最终得到的校验码全为 0,则认为数据传输正确,否则表示数据可能出现

尽管井字游戏玩家只学习了游戏的基本动作,但没有什么能阻止强化学习在更高的水平上发挥作用,因为每个“动作”本身都可能是一种可能精心设计的解决问题的方法的应用。其次,有一个明确的目标,正确的行为需要有计划或远见,考虑到自己选择的延迟影响。强化学习解决方案的一个显著特点是,它可以在不使用对手模型的情况下,也不需要对未来状态和行动的可能序列进行明确搜索的情况下实现规划和前瞻的效果。在井字游戏的例子中,我们