




- @abc31431415926
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
定义:b:分支数(可能为无穷)d:最优解的深度(一定存在)m:搜索树的最大深度(可能为无穷)(1)时间复杂度:O(b^d)(2)空间复杂度:O(b^d)(3)完备性:是(当且仅当b是有限的)(4)最优性:是(当且仅当单步代价相同) 引入单步代价,每次扩展一个代价最小的节点(注意:搜索到某一结点但不一定扩展它,只有当它是当前所有未扩展结点中代价最小时才扩展),第一次被扩展的节点一定是最优解。(当单

激活函数对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。
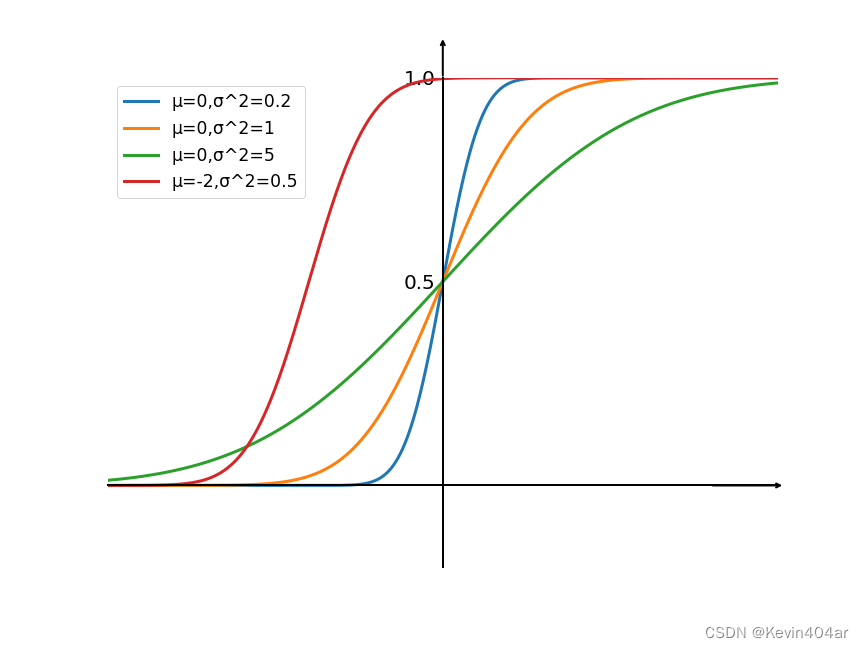
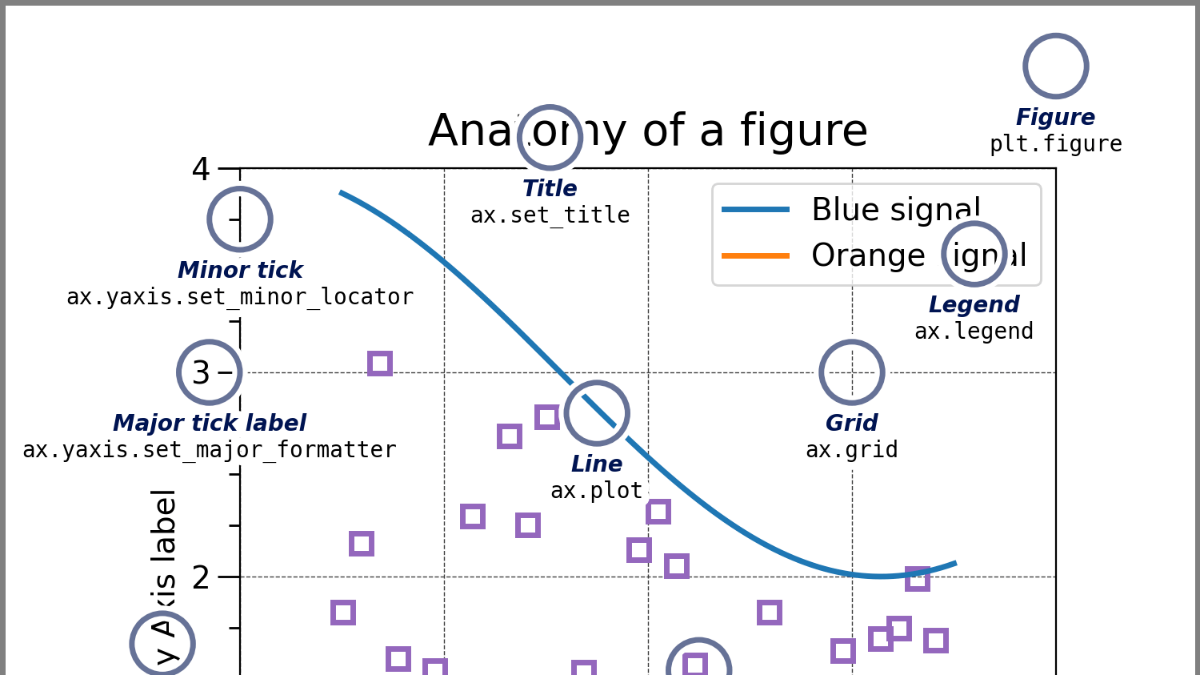
Matplotlib,全称“Matlab plotting library”,是Python中的一个库,它是数字的-NumPy库的数学扩展,是Python中绘制二维和三维图表的数据可视化工具pyplot,面向当前图;axes,面向对象;Pylab,沿用 matlab 风格。Matplotlib中的所有内容都按层次结构组织,层次结构的顶部是由matplotlib提供的matplotlb“状态机环境”
引入物理学中的动量思想,加速梯度下降,梯度下降在不变的维度上,参数更新变快,梯度有所改变时,更新参数变慢,这样就能够加快收敛并且减少动荡。Adadelta的一个特例,当ρ=0.5时,E就变为了求梯度平方和的平均数;momentum的改进,在梯度更新时做一个矫正,具体做法就是在当前的梯度J上添加上一时刻的动量。NAG:(绿色)先在原来动量方向(棕)迈一大步,然后算梯度(红),得到矫正之后的绿色线。(
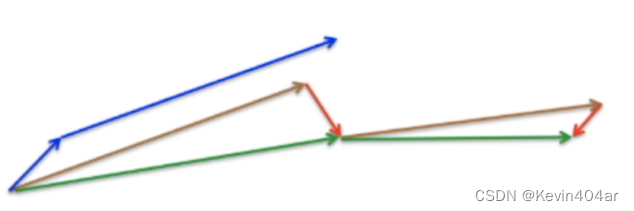
引入物理学中的动量思想,加速梯度下降,梯度下降在不变的维度上,参数更新变快,梯度有所改变时,更新参数变慢,这样就能够加快收敛并且减少动荡。Adadelta的一个特例,当ρ=0.5时,E就变为了求梯度平方和的平均数;momentum的改进,在梯度更新时做一个矫正,具体做法就是在当前的梯度J上添加上一时刻的动量。NAG:(绿色)先在原来动量方向(棕)迈一大步,然后算梯度(红),得到矫正之后的绿色线。(
引入物理学中的动量思想,加速梯度下降,梯度下降在不变的维度上,参数更新变快,梯度有所改变时,更新参数变慢,这样就能够加快收敛并且减少动荡。Adadelta的一个特例,当ρ=0.5时,E就变为了求梯度平方和的平均数;momentum的改进,在梯度更新时做一个矫正,具体做法就是在当前的梯度J上添加上一时刻的动量。NAG:(绿色)先在原来动量方向(棕)迈一大步,然后算梯度(红),得到矫正之后的绿色线。(
通常情况下,一个或者一组优秀的学习率既能加速模型的训练,又能得到一个较优甚至最优的精度。以上两种情况在训练初期以及中期,此时若仍然以固定的学习率,会使模型陷入左右来回的震荡或者鞍点,无法继续优化。在小数据集上,通常微调的效果比从头训练要好很多,因为在于数据量较小的前提下,训练更多参数容易导致过度拟合。对数据的拟合较好,而在实际应用中,也验证了这一点。若有两类超参数,每类超参数有3个待探索的值,对它
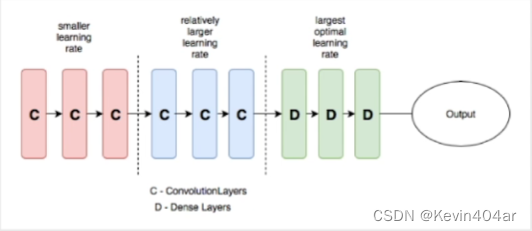
通常情况下,一个或者一组优秀的学习率既能加速模型的训练,又能得到一个较优甚至最优的精度。以上两种情况在训练初期以及中期,此时若仍然以固定的学习率,会使模型陷入左右来回的震荡或者鞍点,无法继续优化。在小数据集上,通常微调的效果比从头训练要好很多,因为在于数据量较小的前提下,训练更多参数容易导致过度拟合。对数据的拟合较好,而在实际应用中,也验证了这一点。若有两类超参数,每类超参数有3个待探索的值,对它
