




- @a394467238
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这两种滤波非常有用,一定要用好;半径滤波:半径滤波器比较简单粗暴。以某点为中心画一个圆计算落在该圆中点的数量,当数量大于给定值时,则保留该点,数量小于给定值则剔除该点。此算法运行速度快,依序迭代留下的点一定是最密集的,但是圆的半径和圆内点的数目都需要人工指定;统计滤波过滤:第一次扫描:对每个点,我们计算它到它的所有临近N个点的平均距离。计算出这些距离的均值和标准差第二次扫描:平均距离在M个标准差范
本文介绍了一种使用深度学习网络的本地化TTS方案,具有空间占用较大、运行速度较慢的缺点,但无需联网调用各大互联网公司的模型接口。随着深度学习技术的发展,特别是循环神经网络(RNN)和卷积神经网络(CNN)的应用,TTS技术得到了显著的改进。目前已有的深度学习TTS方案包括基于端到端(End-to-End)的TTS和基于编码器-解码器(Encoder-Decoder)的TTS等。本文所介绍的方案使用

个人公众号“代码就是生产力”,发布更多有用的工具根据大疆的协议解析的LVX文件,并用open3d 显示出来,LVX文件是从大疆官网下载的地平线雷达的数据,其他雷达的数据应该也可以解析。直接放效果和代码吧20210602_131722lonlon ago的视频· 7 播放代码写的很直接简单,打开文件,解析,显示,没有什么其他的步骤,有问题可以留言。#coding:utf-8import struct
该自动批量查询工具的目的是给一些代记账的公司使用,可以让他们快捷的知道目前有哪些公司需要进行哪些项目的申报, 因为他们需要给很多家公司进行报账,多的有四五百家,普遍做法是在税务系统每次都人工登录每个公司,然后查看公司申报状态后进行操作,这样的一个弊端就是效率很低,并且登录进去后发现有的公司还没有可以申报的信息出来,进一步降低了效率;市面上也有一些代记账软件可以实现类似的功能,但是普遍价格较贵;使用
使用了目前已有的音频识别的深度学习网络,然后封装成了一个单独的模块,使用的方法就是下载软件,然后打开音频所在的文件夹就行了,会自动扫描wav, mp3 后缀结尾的文件并执行转换。作为一个业余的软件开发爱好者,我又捣鼓了一个有意思的小东西 ,使用完全免费哈。
多个激光雷达外参标定 python程序

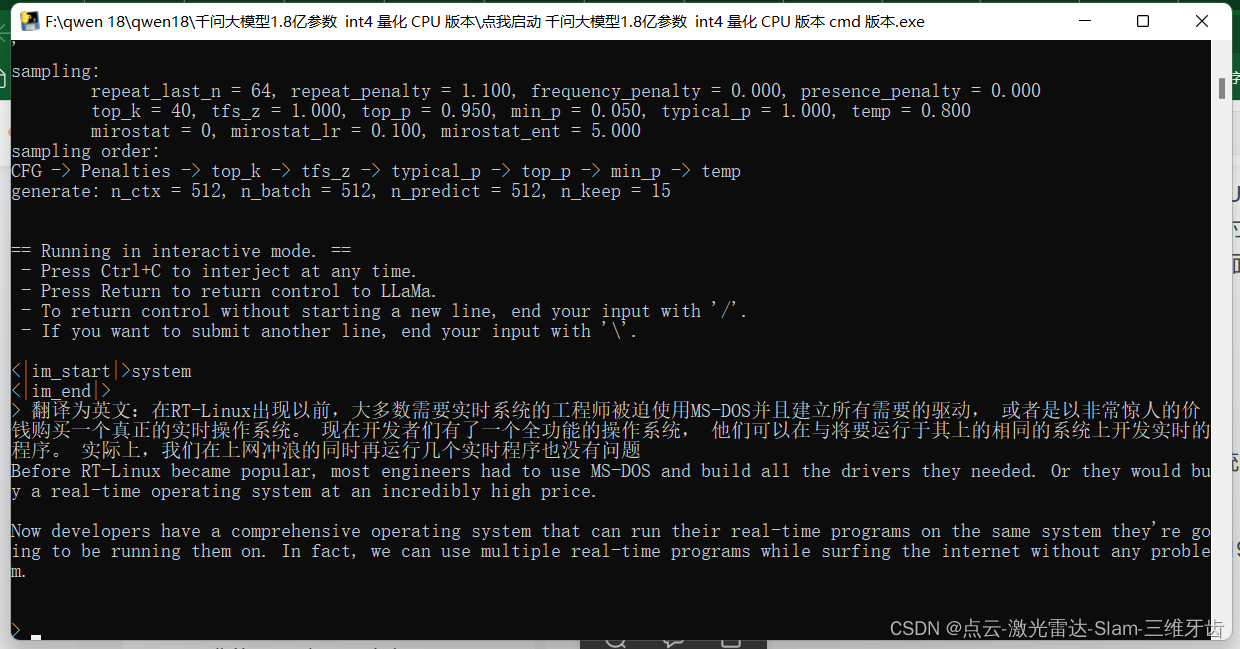
关键是,之前我6G显存的电脑跑很多大模型本地都跑不起来,甚至很多6B的模型都报错显存溢出,这应该是对没有显存或者显存小于8G的用户最友好的中文本地大模型了,所以我通过 llama.cpp 量化部署然后把模型打包成了一个可以本地离线单独使用的整合包,我自己测试了一下它的对话能力,基本ok, 比起以往的小参数大模型效果好蛮多。打开软件后会自动打开浏览器的一个网页,不要修改默认的参数,在最下方有一个框框
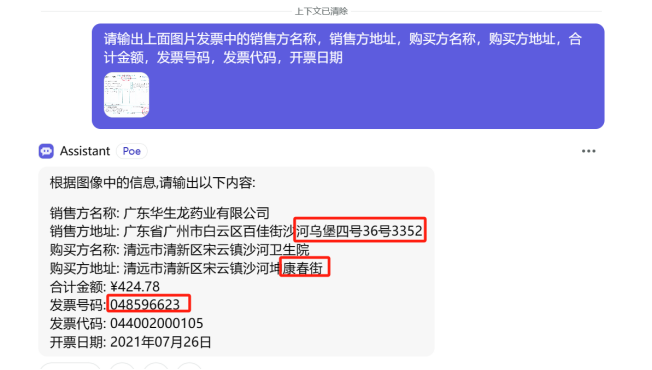
测试包含大模型: 百度的文心一言3.5, 字节的豆包大模型, 阿里通义千问2.5 , 百川智能 , 智谱GLM4, 科大讯飞的星火, 月之暗面kimi,GPT-3.5,GPT-4o,海螺ai,Deepseek。文心一言, 没有理解我的需求并且错误的格式返回了,3.5 输出格式比较混乱,一股脑的输出OCR结果,总体精度勉强,不能用;效果嘎嘎好,让我惊艳,理解了我的需求并且正确的格式返回了,甚至给的有
摘要:本文介绍了一款通用票据信息提取工具,支持PDF和图片格式的各类票据(如发票、机票、保险单等)批量处理。软件采用OCR+大模型技术,操作简单仅需三步:选择文件夹、识别样本选择字段、批量提取并自动保存。相比之前版本,新增支持任意格式票据处理,并能区分电子PDF(可选中文字)与非电子PDF(需OCR识别)。下载地址附后。
只需要在原始点云中采样几个视角点,就可以很平滑的生成点云漫游视频,效果也很酷炫,可以切换色彩渲染方案,生成的视频为avi格式下载地址:https://pan.baidu.com/s/1WQQ8kaDilaagjoK5IrYZzA提取码:1111