- @Zyzyzyzyzzzz
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文系统复盘GPT预训练、RLHF、ChatGPT、多模态与智能体的八年演进,并延伸至算力、权限和治理边界。
本文系统复盘GPT预训练、RLHF、ChatGPT、多模态与智能体的八年演进,并延伸至算力、权限和治理边界。
本文系统复盘GPT预训练、RLHF、ChatGPT、多模态与智能体的八年演进,并延伸至算力、权限和治理边界。
本文系统复盘GPT预训练、RLHF、ChatGPT、多模态与智能体的八年演进,并延伸至算力、权限和治理边界。
这篇文章系统复盘了大模型全量SFT、LoRA、QLoRA微调与AWQ/GPTQ量化技术的底层原理、显存精算及工程落地决策。

本文概述大模型中的精度类型(浮点与整数)及四种主流量化方法(NF4、GPTQ、AWQ、GGUF),对比其原理、优缺点与适用场景。
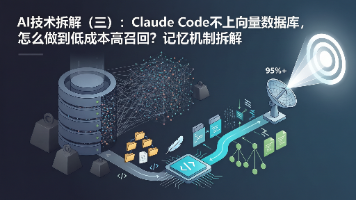
主要介绍claude code常用的快捷键。

Claude Code三层记忆架构:长期记忆层(CLAUDE.md与MEMORY.md)实现跨会话持久化;当前轮召回层通过语义匹配加载记忆,并采用Session Memory动态压缩上下文;会话持久层完整保存对话日志。该设计兼顾智能检索与成本控制。
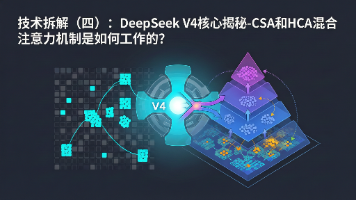
DeepSeek V3以MLA低秩压缩KV缓存,结合DSA闪电索引器动态筛选Top-k Token做稀疏注意力,将复杂度从O(L²)降至O(Lk)。DeepSeek V4进一步提出HCA+CSA混合架构:HCA以128:1激进压缩并采用FP4精度存储,CSA以4:1保守压缩后索引筛选再做MLA,两者交替堆叠,在百万Token长上下文下实现FLOPs降至27%、KVCache降至10%