




- @ZuanShi1111
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
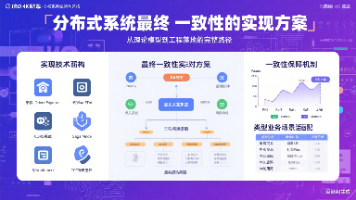
摘要:本地消息表是分布式系统中实现最终一致性的轻量级方案,通过将分布式事务拆分为多个本地事务,利用数据库事务特性确保业务操作与消息记录的原子性。核心模块包括:消息表设计(存储消息状态与内容)、本地事务与消息写入(保证业务与消息的原子性)、消息发送与重试(定时扫描并可靠投递)。该模式通过牺牲强一致性换取高可用性,适用于电商订单等对实时一致性要求不高的场景,依靠重试机制和幂等处理确保数据最终一致。代码
摘要: 本文对比了分布式训练的三大引擎(DDP、FSDP、DeepSpeed)的原理与适用场景,并基于LLaMA-Factory框架提供实战案例。DDP适合中小模型(如7B),通过数据并行实现梯度同步;FSDP通过参数分片降低显存占用,支持70B级大模型训练;DeepSpeed提供ZeRO优化和Offload功能,适用于超大规模模型。实战部分详细展示了7B模型(4卡DDP)和70B模型(16卡FS
摘要:制造业大模型成本控制四步法 硬件上按需选型(云端/自有混合部署,GPU适配模型规模,复用边缘设备),降低30%采购成本;训练中优化参数(混合精度/合理batch size)与框架(DeepSpeed加速),结合数据增强和主动学习减少标注量,缩短周期50%;运维通过自动化工具(Ansible/Prometheus)减少60%人工操作;场景落地优先选择高ROI应用(如质检/预测性维护),避免重复
摘要:本文深入解析MySQL事务机制,从ACID特性原理到实战应用。首先解释原子性(通过undo log实现)、一致性(数据状态保障)、隔离性(并发控制)和持久性(redo log保证)四大特性。接着对比四种事务隔离级别(读未提交、读已提交、可重复读、串行化)的特点及适用场景,并介绍MVCC多版本并发控制的实现原理。最后提供事务优化技巧,包括控制事务大小、预防死锁、合理使用索引等,帮助开发者提升数

摘要:本文深入探讨Langchain框架中大语言模型(LLM)长期记忆的设计与实现,重点分析基于MySQL和MongoDB的存储方案。长期记忆通过跨会话数据存储支持个性化交互和复杂任务推进,但面临数据规模与查询效率的挑战。MySQL适合结构化数据,通过规范化表设计和事务保障数据一致性;MongoDB则擅长半结构化数据,以灵活文档模型实现高效存储与检索。文章详细对比了两者的核心架构、读写流程及适用场
摘要:本文对比了传统数据库与向量数据库在数据存储、查询方式、适用场景等方面的差异。传统数据库适用于结构化数据的精确查询和事务处理,而向量数据库擅长处理非结构化数据(如文本、图像)的语义搜索和相似性匹配。传统数据库使用B树等索引支持精确查询,向量数据库则采用HNSW等索引实现高效相似性搜索。向量数据库在推荐系统、NLP、图像检索等AI场景优势明显,但其数据更新和存储计算成本较高。两者各有适用场景,选
LoRA(低秩适应)是一种高效的大模型微调技术,通过在Transformer层中引入可训练的低秩矩阵来替代全量参数更新,显著降低计算成本。其核心思想是将权重增量矩阵分解为两个小矩阵的乘积(ΔW=A·B),使参数量从d×k降至r×(d+k)。该技术适用于注意力模块和前馈网络,在保持模型性能的同时大幅减少训练资源。文章通过情感分析和文本分类案例展示了LoRA的实际应用,包括代码实现和参数配置,验证了其
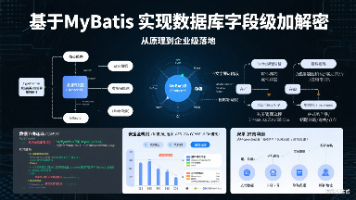
本文深度剖析了基于MyBatis实现数据库字段级加解密的技术方案。通过自定义注解标记敏感字段,利用MyBatis拦截器机制,在数据写入数据库前进行加密,在查询返回结果后进行解密。文章详细介绍了输入拦截器(ParameterHandler)和输出拦截器(ResultSetHandler)的实现原理,并提供了完整的代码示例。该方案实现了对业务层透明的数据安全保护,有效保障了敏感数据在存储和传输过程中的
本文介绍了分布式锁框架Lock4j的核心原理与SpringBoot整合实战。Lock4j支持Redis、Zookeeper等多种锁实现,提供注解驱动、自动续期等特性,通过原子操作确保分布式系统并发安全。实战部分演示了基于Redis的库存扣减案例,包含依赖配置、注解使用和并发测试,并扩展了Zookeeper实现方式。文章还涵盖自定义Key生成策略和锁执行器的高级用法,帮助开发者灵活应对复杂业务场景。

摘要: CAP定理是分布式系统设计的核心理论,指出一致性(C)、可用性(A)和分区容错性(P)三者不可兼得,需权衡选择。实际应用中,由于网络分区不可避免(P必选),系统通常需在CP(强一致性,如银行系统)或AP(高可用性,如电商库存)间取舍。文章通过ZooKeeper分布式锁的代码示例,展示CP系统如何通过牺牲可用性确保数据一致性,并对比不同场景下的技术选型(如MongoDB、HBase等)。理解
