




- @Zssss12
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
虽然人们对用自然语言描述视频的任务越来越感兴趣,但目前的计算机视觉算法在视频及其可以识别的相关语言的可变性和复杂性方面仍然受到严重限制。这在一定程度上是由于当前基准测试的简单性,这些基准测试主要集中在特定的细粒度领域,具有有限的视频和简单的描述。虽然研究人员已经为图像字幕提供了几个基准数据集,但我们不知道有任何大规模的视频描述数据集具有全面的类别和多样化的视频内容。在本文中,我们提出了MSR-VT

要理解深度学习中的优化器,核心是从 “如何高效更新模型参数以最小化损失” 这一问题出发,按 “基础→改进→融合” 的逻辑梳理。以下从最简单的优化器开始,逐步深入复杂方案,每个优化器均包含,帮助清晰理解演进脉络。
ROS 分布式通信是 “机器人内部的专业通信”,适配 Linux 环境下的节点间交互,但跨平台、跨设备能力弱;Socket(如 Socket.IO)是 “通用跨平台通信”,解决 ROS 无法对接 Web / 手机 / 非 ROS 设备的问题;两者是互补关系:ROS 管机器人内部,Socket 管机器人对外,共同覆盖 “内部控制 + 外部交互” 的全场景;核心取舍:只做机器人内部模块通信 → 用 R
FashionMNIST(时尚MNIST)是一个经典的计算机视觉数据集,用于图像分类任务。它是由 Zalando Research 创建的,旨在替代传统的MNIST数据集,以更贴近实际场景中的图像分类问题。FashionMNIST数据集包含了60,000个用于训练的图像样本和10,000个用于测试的图像样本,总共包括10个类别。每个样本都是灰度图像,分辨率为28x28像素。每个像素的值介于0到25

FashionMNIST(时尚MNIST)是一个经典的计算机视觉数据集,用于图像分类任务。它是由 Zalando Research 创建的,旨在替代传统的MNIST数据集,以更贴近实际场景中的图像分类问题。FashionMNIST数据集包含了60,000个用于训练的图像样本和10,000个用于测试的图像样本,总共包括10个类别。每个样本都是灰度图像,分辨率为28x28像素。每个像素的值介于0到25
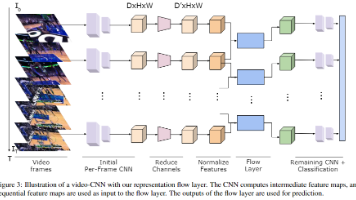
在本文中,我们提出了一种受光流算法启发的卷积层来学习运动表示。我们的表示流层是一个完全可微的层,旨在捕获卷积神经网络中任何特征通道的“流”以进行动作识别。它用于迭代流优化的参数以端到端的方式与其他 CNN 模型参数一起学习,最大化动作识别性能。此外,我们通过堆叠多个表示流层来新引入的学习“流流(flow of flow)”表示的概念。我们进行了广泛的实验评估,证实了它在计算速度和性能方面优于传统的
要理解深度学习中的优化器,核心是从 “如何高效更新模型参数以最小化损失” 这一问题出发,按 “基础→改进→融合” 的逻辑梳理。以下从最简单的优化器开始,逐步深入复杂方案,每个优化器均包含,帮助清晰理解演进脉络。
Conda和Docker在Python项目中各有侧重:Conda专注于解决Python包依赖和版本隔离问题,适用于开发环境管理;Docker则提供系统级隔离,确保从开发到部署的全环境一致性。两者的核心区别在于隔离级别、依赖管理范围和可移植性。实际项目中常配合使用:开发阶段用Conda管理Python依赖,部署时通过Docker打包完整环境,实现"开发即生产"的目标。根据需求选择
以前常看到许多著名的模型中(Transformer,SwinTransformer...)都存在着归一化操作,当时只道是寻常,了解了大概功能和其存在的意义之后就没再深研究,最近自己上代码打算着手实战,相对这个歌操作进行一个概要的梳理,重点在与原理与应用,至于设计者的构思不做详细阐述。
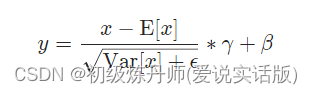
FashionMNIST(时尚MNIST)是一个经典的计算机视觉数据集,用于图像分类任务。它是由 Zalando Research 创建的,旨在替代传统的MNIST数据集,以更贴近实际场景中的图像分类问题。FashionMNIST数据集包含了60,000个用于训练的图像样本和10,000个用于测试的图像样本,总共包括10个类别。每个样本都是灰度图像,分辨率为28x28像素。每个像素的值介于0到25