




- @ZhongGuoZhiChuang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
col.DATA_DEFAULT AS "默认值",col.COLUMN_NAME AS "列名",col.DATA_TYPE AS "数据类型",col.DATA_TYPE AS "字段类型",col.DATA_LENGTH AS "长度",col.TABLE_NAME AS "表名",col.NULLABLE AS "是否为空",comm.COMMENTS AS "备注"col.OWNER A

Spark的bin目录中的 spark-submit脚本用于启动集群上的应用程序。它可以通过统一的接口使用Spark的所有支持的集群管理器,因此您不必为每个集群管理器专门配置您的应用程序捆绑应用程序的依赖关系如果您的代码依赖于其他项目,则需要将它们与应用程序一起打包,以便将代码分发到Spark集群。为此,请创建一个包含代码及其依赖关系的程序集jar(或“uber”jar
col.DATA_DEFAULT AS "默认值",col.COLUMN_NAME AS "列名",col.DATA_TYPE AS "数据类型",col.DATA_TYPE AS "字段类型",col.DATA_LENGTH AS "长度",col.TABLE_NAME AS "表名",col.NULLABLE AS "是否为空",comm.COMMENTS AS "备注"col.OWNER A
TimeUnit 表示给定单元粒度的时间段,它提供在这些单元中进行跨单元转换和执行计时及延迟操作的实用工具方法。TimeUnit 不维护时间信息,但是有助于组织和使用可能跨各种上下文单独维护的时间表示形式。毫微秒定义为千分之一微秒,微秒为千分之一毫秒,毫秒为千分之一秒,一分钟为六十秒,一小时为六十分钟,一天为二十四小时。方法详细信息valuespublic static fin
【代码】python 对比数据库,生成sql。

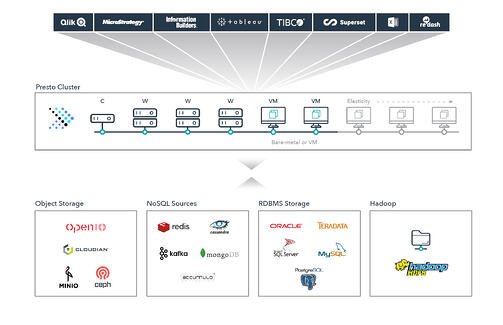
过去的相当长的一段时间里,商用对象存储占据了市场上的大量的份额。国外的Amazon S3,国内的阿里云OSS都成为了大多数公司的选择。但是构建一个企业级的数据湖(包括结构化和非结构化数据)已经成为了越来越多公司的目标。那么Hadoop还能满足我们的要求吗?还是我们需要更多的选择?存储方案如图所示,底层存储大体可以分为四类。对象存储(Object Storage),NoSQL 数据库(NoSQL S
linux服务器内网磁盘映射、文件夹共享存储1、当前局域网两台服务器:服务器1:192.168.1.2服务器2:192.168.1.3如果是虚拟机或者云主机需要在安全组增加允许tcp 任何端口 访问 192.168.1.0/24想把服务器2:192.168.1.3的某个文件夹或某块磁盘挂载到服务器1:192.168.1.2的/home/share路径进行文件同步存储2、开始设置2.1 服务器1:1
Java内存模型Java内存模型,往往是指Java程序在运行时内存的模型,而Java代码是运行在Java虚拟机之上的,由Java虚拟机通过解释执行(解释器)或编译执行(即时编译器)来完成,故Java内存模型,也就是指Java虚拟机的运行时内存模型。Java虚拟机在执行Java程序过程中会把它所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着Java虚
概述介绍当前状态时间轴结构部署配置运行时间线服务器通过命令行访问通用数据发布应用程序的具体数据时间线服务器REST API通用数据REST API概述介绍通过时间轴服务器在YARN中以通用方式存储和检索应用程序的当前和历史信息。它有两个责任:坚持应用程序特定信息收集和检索完全具体到应用程序或框架的信息。例如,Hadoop MapReduc
在spark1.3版本后,kafkautil里面提供了两个创建dstream的方法,1、KafkaUtils.createDstream构造函数为KafkaUtils.createDstream(ssc, [zk], [consumer group id], [per-topic,partitions] ) 使用了receivers来接收数据,利用的是Kafka高层次的消费者a