




- @WenW1217
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如各位开发者所熟悉的,在编写C++,或者阅读大量源码的时候,会遇到一个名为std :: bind的函数。该函数能够将对象绑定到函数或者可调用对象上。在一些情况下具有非常实用的效果。但是在早期 C++ 中有一个问题,那就是std :: bind能传入的参数非常有限,虽然在多数情况下能满足需求,但总有非常棘手的情况。这个问题直到 C++11 引入了变参模板的新特性才得以解决。本文主要讲解在 C++11

sort函数允许你通过提供自定义比较函数来控制排序方式。

都扮演着至关重要的角色。它不仅能够确保一个类只有一个实例存在,还能够提供全局访问点,使得我们可以方便地在程序的任何地方使用该实例。注意:设计模式虽然是理论概念上的内容,但最终的落实是以 code 的形式。自己创建:类自己负责生这个对象,不让外面随便用 new 关键字,构造函数通常私有。全局访问:有个统一入口能拿到这个对象,哪里需要哪里拿,不用到处传。唯一实例:整个系统里这个类只活一个对

C++ 支持类型的重载,使得外部在调用对象的时候能够在某些情况下达到使用类似目标类型的效果。使用静态对象可以减少临时对象的生成,但是提升效率的同时往往会造成许多意想不到的问题。分别对应拷贝赋值和移动赋值。请同时出现让外部人员认为行为的一致。一般对应左右值重载的情况不多,此处以 const 重载为例。就像是在工厂模式中一样,有构造工厂的同时要提供析构工厂。C++ 非常重要的两个构造,拷贝构造和移动构

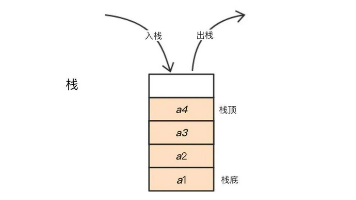
当我们浏览网页时,每次点击链接都会将新的页面加入到栈中,而当我们点击 “返回” 按钮时,就会将栈顶的页面弹出,这样就可以回到之前的页面了。队列的本质也是一个容器,它可以存储任何类型的数据,但是队列的大小也是固定的。栈的基本操作有两个,即入栈和出栈。栈的本质是一个容器,它可以存储任何类型的数据,但是栈的大小是固定的,因为它的元素只能在栈顶添加或删除。当一个进程需要运行时,就将它加入到队列的队尾,当操
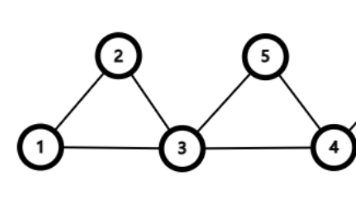
我们发现,节点 还存在未被遍历的边( 和 ),因此我们从节点 出发,重复步骤 1。将结果序列中的一个 换成这个回路,此时的结果序列即为 ,而图也变成了下面的样子。将结果序列中的一个 换成这个回路,此时的结果序列即为 ,而图也变成了下面的样子。我们通过反证法简要说明一下,为什么步骤 1 中,如果遇到一个节点 不存在未被删除的边(即节点 的度数为 ),那么该节点必然是出发点。首先,假设 ,那么在遍历过
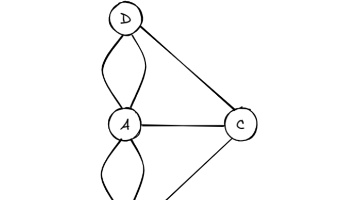
同样地,对于起点而言,离开起点需要“消耗”一条边,而回到起点需要“消耗”另一条边。因此,该节点的度数(连接该节点的边的数量,若一条边的两端是同一个节点则需计算两次)必须为偶数,才能保证我们不被“困在”该节点中。欧拉对哥尼斯堡七桥问题的分析更加抽象化。首先,欧拉将每片地区抽象为一个点,并将每座桥抽象为连接两点的一条线,得到如下抽象图形。与上一节中的分析类似,对于任意一个与起点不同的节点,进入该节点需
如果 pairs 的一个重新排列,满足对每一个下标 i(1 <= i < pairs.length)都有 endi-1 == starti,那么我们就认为这个重新排列是 pairs 的一个合法重新排列。然而,设 pair 的数量有 个,这样构建的图将有 条边(考虑 个 pair 满足 end == 1,另外 个 pair 满足 start == 1 的数据),无法满足本题的数据范围。更妙的是,我们

如果 pairs 的一个重新排列,满足对每一个下标 i(1 <= i < pairs.length)都有 endi-1 == starti,那么我们就认为这个重新排列是 pairs 的一个合法重新排列。然而,设 pair 的数量有 个,这样构建的图将有 条边(考虑 个 pair 满足 end == 1,另外 个 pair 满足 start == 1 的数据),无法满足本题的数据范围。更妙的是,我们
如大家所熟悉的,程序员在学操作系统的时候一般都会接触一个经典问题——哲学家进餐问题,有 5 个哲学家围着在一个圆桌上,而圆桌上正好放有 5 根筷子,每根筷子放在两个哲学家之间,就在这两个人的左 / 右手边,并且这两个哲学家都能拿起筷子,哲学家进餐有规定:每个人只能拿起左手边和右手边的筷子,如果没有两根筷子,就不能进餐,每个人进餐结束之后将筷子放回原处。总之,多线程是有很多知识点需要总结的,学习了多
