




- @Sun_Weiss
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一、Power BI 支持的数据源类型Power BI支持广泛的数据源类型,包括文件、数据库、云服务和其他来源。文件:Excel、文本/CSV、XML、JSON、文件夹、PDF等。数据库:SQL Server, Oracle, IBM DB2, MySQL, PostgreSQL等。云服务:Azure SQL Database, Azure Blob Storage, Salesforce, Go

多个分类的比例或数值,需要找到每一行最大的5个(或者n个)比例或数值,以及它们对应的类别,并输出
机器学习的模式:用训练集的数据,匹配一种算法,生成一个函数(h),这个函数可以输入x,产出y所以机器学习的关键在于:1、选择正确的算法,选择算法之后,函数h的形态就确定了,但是参数未知2、确定函数h的参数值:监督学习:通过训练集的x和y,共同确定参数值无监督学习:通过训练集的x,确定参数值最简单的算法:一元 线性回归(Linear Regression)相同的算法,不同的参数值:成本函数(Cost
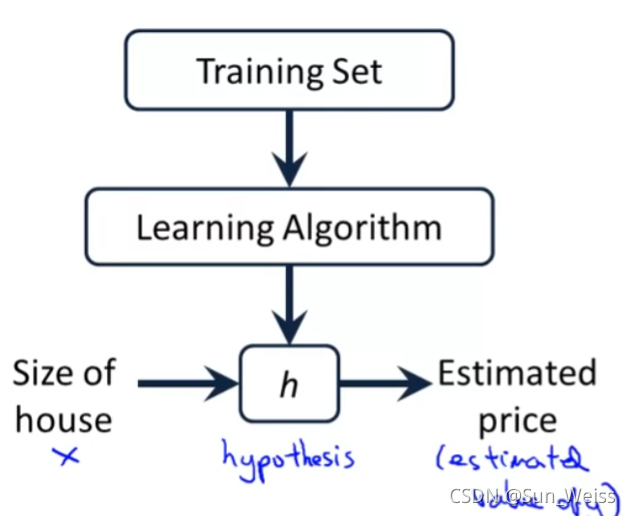
吴恩达课程中,代码是用Octave写的,分为两个部分:1、定义代价函数;% 定义代价函数 Jfunction J = costFunctionJ(X, y, theta)m = size(X, 1); % 样本量predictions = X * theta; % 预测值sqrErrors = (predictions - y) .^2; % 预测值与真实值的方差J = 1/(2*m) * sum
(但这种关系创建往往是直接在不同表的同名字段间创建关系,不一定是我们想要的关系,还可能会导致后续数据分析的错误。表之间可以存在多个关系,但同时只能有一个关系处于活动状态(在模型关系图中用实线表示),其他的关系则处于非活动状态(用虚线表示)。不建议使用,因为如果两个表之间是一对一的关系,那更好的方法是把这两个表合并成一个。两个表的对应关系,关系是有次序的,分为左表和右表,两个表之间有多对一、一对一、
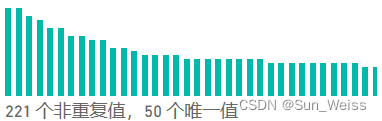
Power Query 的列分布、列质量、列概要功能,可以在没有进入分析之前,就粗略查看这列数据的分布和统计信息,方便数据的整理和清洗。
2、视觉对象格式tab,(1)选择一周从哪一天开始(我们一般从周一开始);(2)选择一行显示几个月的日历(我选择了6个,一年分两行展示);(3)选择数据最大值的颜色(最小值为白色,中间颜色渐变)1、视觉对象tab,将日期拖入Date栏,将数据指标拖入Values栏。原图是用 d3 做的,我想用 Power BI 实现同样的展示效果。《数据可视化》这本书里介绍了一个时间可视化的案例(如下图所示),这

(但这种关系创建往往是直接在不同表的同名字段间创建关系,不一定是我们想要的关系,还可能会导致后续数据分析的错误。表之间可以存在多个关系,但同时只能有一个关系处于活动状态(在模型关系图中用实线表示),其他的关系则处于非活动状态(用虚线表示)。不建议使用,因为如果两个表之间是一对一的关系,那更好的方法是把这两个表合并成一个。两个表的对应关系,关系是有次序的,分为左表和右表,两个表之间有多对一、一对一、