




- @Scientifical
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
论文:https://arxiv.org/abs/2502.06314会议:https://so.csdn.net/so/search?q=ECCV&spm=1001.2101.3001.7020年份:2025自监督学习(Self-Supervised Learning, SSL)无需人工标注,通过 “设计辅助任务” 从无标签数据中学习有意义的特征表示,目标是让学习到的表示能迁移到下游任务主成分分
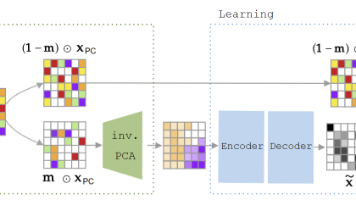
提出了一种名为 L-MAE(标签掩码自编码器) 的创新方法,旨在解决语义分割数据集制作成本高且标注易出错的问题。该模型首次将掩码自编码器(MAE)架构应用于下游的标签补全任务,通过一种 Stack Fusion(堆栈融合) 策略将不完整的标签与原始图像融合,并利用 Image Patch Supplement(图像块补充) 算法在重建过程中引入视觉引导,从而实现像素级的精准标签修复。实验证明,L-
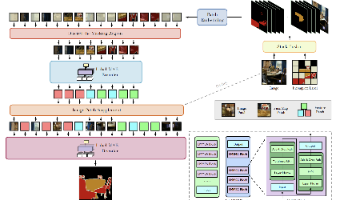
监督预训练的 “epoch 饱和” 问题显著组件设计的适配性与通用性不足模型架构适配性单一:实验主要基于 ViT-B/16 验证,仅在 SimMIM+Swin-Base 上做了简单兼容性测试(表 7,精度提升 0.2%),未深入探索在更大模型(如 ViT-L/H)、 hierarchical 架构(如 Swin-V2、ConvNeXt)上的表现,难以验证方法对不同视觉 Transformer 的普
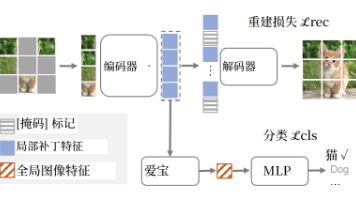
监督预训练的 “epoch 饱和” 问题显著组件设计的适配性与通用性不足模型架构适配性单一:实验主要基于 ViT-B/16 验证,仅在 SimMIM+Swin-Base 上做了简单兼容性测试(表 7,精度提升 0.2%),未深入探索在更大模型(如 ViT-L/H)、 hierarchical 架构(如 Swin-V2、ConvNeXt)上的表现,难以验证方法对不同视觉 Transformer 的普