- @S_winner_S
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
但是VAE生成图的质量普遍不高,有人认为原因是因为VAE把图片编码成了连续的变量,但是我们在描述物体时,转化为离散变量会更为自然。如果我们能够限制住AE的编码空间,使其能够符合某个数学分布,比如标准正态分布,那么我们就可以在标准正态分布中随机采样给Decoder,那么就能够生成随机的图了。VQVAE的作者的做法是,通过PixelCNN随机在数学分布中采样,生成小图像,再用VQGAN的decoder

24年8月,stable diffusion前核心团队成员组建的黑森林实验室公布了一款文生图模型——FLUX.1, 效果惊艳四座,不仅克服了stable diffusion, SDXL等一众模型画手错乱的问题,在图片质量、精细程度以及图片细节、风格多样性上碾压了一众模型,达到了当时的SOTA水平。因此本文将带领大家,从源码上来学习该模型的思想。

Dit来自论文《Scalable Diffusion Models with Transformers》,是构成Sora文生视频的核心。在Stable Diffusion中,image被压缩到latents之后,会继续被送到unet构建的attention中,然后再DIT中,作者把unet进行了替换,而使用Transformer。在推理速度和质量上达到了SOTA。

寻找字体(物体)的轮廓在深度学习(尤其是语义分割)中具有重要的应用,而这次应用的目标就是使用opencv寻找出字体的轮廓,然后通过轮廓找出字体的笔画,以期待能够找出深度学习模型未识别出的笔画。Canny能够适用于许多复杂的情况,而findContours只能够适用简单的字体。

想要实现照片风格转和油画风格互转吗?想要实现斑马野马互转吗?想要实现苹果橘子互转等这些任务吗?没错,CycleGAN网络就能够帮你满足这一目标!

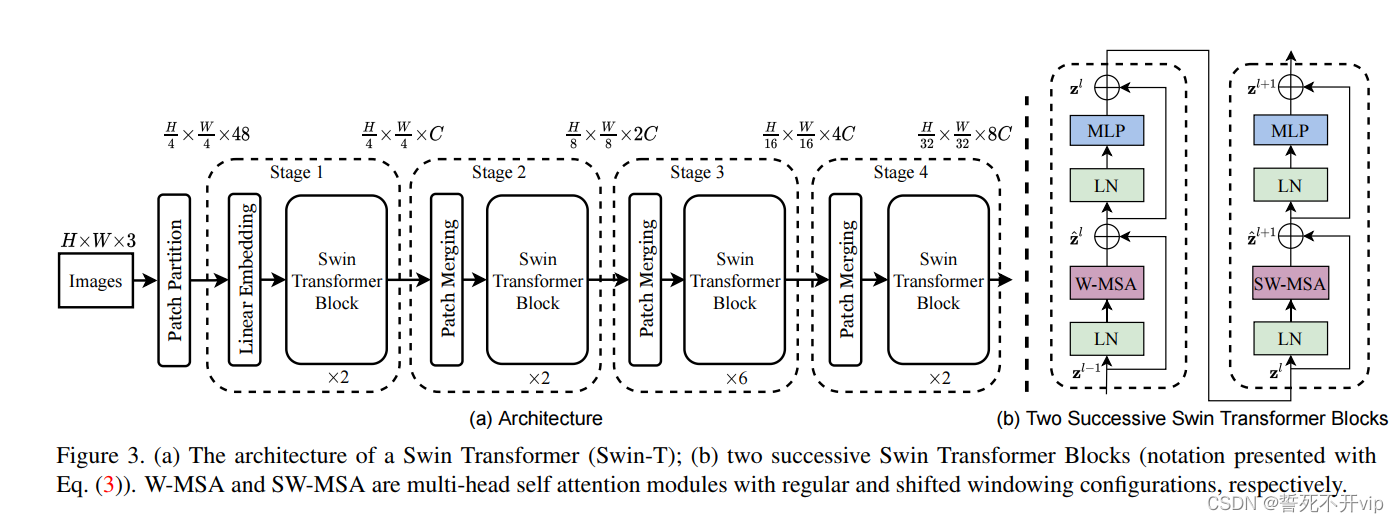
这篇文章主要讲述的是swin transofmrer这个基本的网络架构。虽然现在是2023年,离swin transformer发布已经相隔三年之久了,但是这篇文章点此直达依然在很多下游任务中表现出SOTA的水平。点击直达。