




- @SWZ156
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
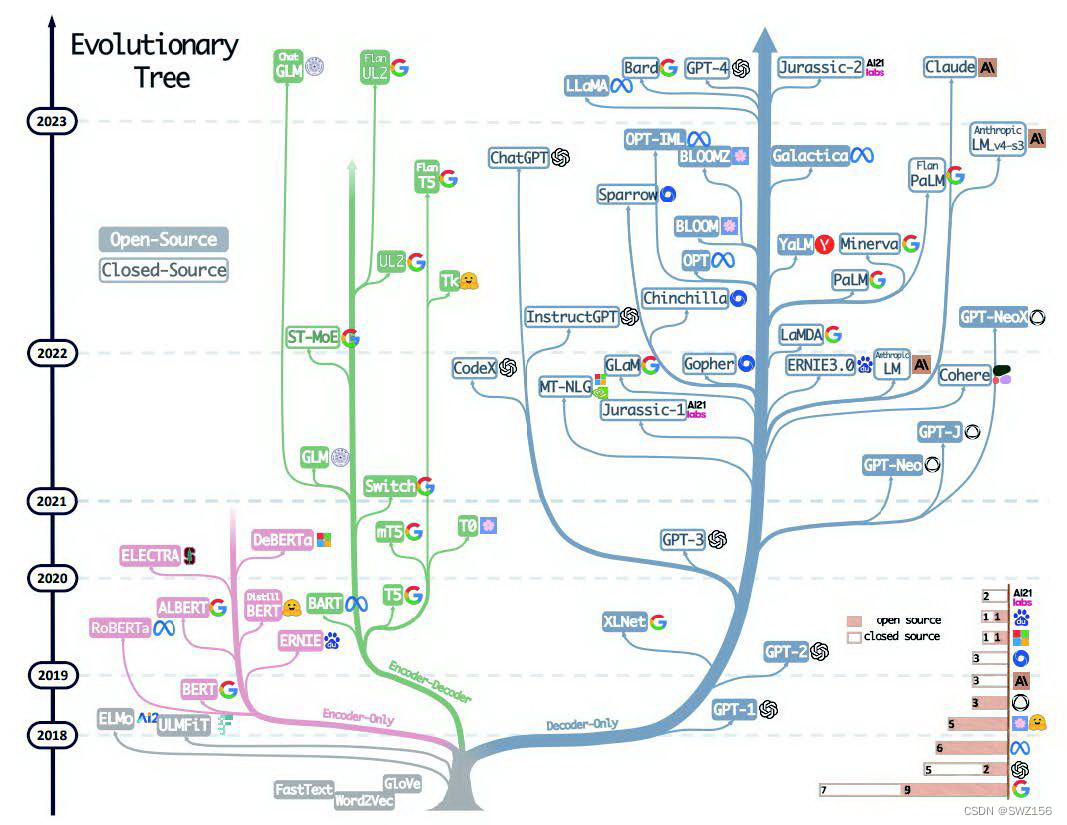
大模型通常指的是参数规模极大的深度学习模型,例如近年来流行的GPT系列、BERT、T5等。大模型的崛起得益于硬件计算能力的提升以及大规模数据的可用性,特别是在云计算和分布式计算技术的发展下,这类模型的训练和推理得以实现。下面是关于大模型的详细介绍。随着硬件技术的进步和新的训练方法的出现,大模型的发展前景广阔。广泛的适用性:同一个大模型可以通过微调适应不同的任务,从而节省了为每个任务单独训练模型的时
【代码】keras实现swin_transformer。

代表的有openai的GPT,meta的Llama。在Decoder-Only模型架构中,模型只包含一个解码器,没有编码器。优点:专注于生成部分,能够生成连贯、有创造性的文本,灵活性高。代表的有Google的T5模型,清华的GLM。优点:灵活强大:能够理解复杂输入并生成相关输出。缺点:架构复杂:相比单一的Encoder或Decoder,它更复杂。代表的有google的bert模型。优点:强大的理解
PyTorch 中的 Tensor 是深度学习模型的核心数据结构。通过本文,你应该对张量的创建、属性、基本操作以及如何在深度学习中应用有了更深入的了解。在实践中,你会发现 PyTorch 提供了非常丰富的功能,助力你构建和优化神经网络模型。

大模型通常指的是参数规模极大的深度学习模型,例如近年来流行的GPT系列、BERT、T5等。大模型的崛起得益于硬件计算能力的提升以及大规模数据的可用性,特别是在云计算和分布式计算技术的发展下,这类模型的训练和推理得以实现。下面是关于大模型的详细介绍。随着硬件技术的进步和新的训练方法的出现,大模型的发展前景广阔。广泛的适用性:同一个大模型可以通过微调适应不同的任务,从而节省了为每个任务单独训练模型的时
代表的有openai的GPT,meta的Llama。在Decoder-Only模型架构中,模型只包含一个解码器,没有编码器。优点:专注于生成部分,能够生成连贯、有创造性的文本,灵活性高。代表的有Google的T5模型,清华的GLM。优点:灵活强大:能够理解复杂输入并生成相关输出。缺点:架构复杂:相比单一的Encoder或Decoder,它更复杂。代表的有google的bert模型。优点:强大的理解
PyTorch 中的 Tensor 是深度学习模型的核心数据结构。通过本文,你应该对张量的创建、属性、基本操作以及如何在深度学习中应用有了更深入的了解。在实践中,你会发现 PyTorch 提供了非常丰富的功能,助力你构建和优化神经网络模型。
vLLM是一款高性能的LLM推理引擎,它针对大语言模型的推理任务进行了优化,特别适合处理并行性和大规模部署的需求。其设计核心是通过创新的“动态批处理”和“连续缓存”来最大化GPU的利用率,同时减少内存占用与数据传输开销。这些技术突破让vLLM在推理速度和硬件资源消耗之间找到了平衡,使得它成为大规模、多用户并发场景下的一种理想选择。

LLaMa-Factory是一个基于人工智能技术的开源项目,专为大型语言模型(LLMs)的微调而设计。它提供了丰富的工具和接口,使得用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景。