- @RandyHan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
PDF之神,大模型时代智能文档处理引擎,是文档的“照相机”,更是信息的“翻译官”,能将杂乱的版面直接“翻译”成规整的结构化数据。10月16日,百度正式发布并开源自研多模态文档解析模型PaddleOCR-VL,该模型在。在文档解析四大核心能力纬度上,PaddleOCR-VL实现全线SOTA,刷新全球OCR VL模型性能天花板。

PDF之神,大模型时代智能文档处理引擎,是文档的“照相机”,更是信息的“翻译官”,能将杂乱的版面直接“翻译”成规整的结构化数据。10月16日,百度正式发布并开源自研多模态文档解析模型PaddleOCR-VL,该模型在。在文档解析四大核心能力纬度上,PaddleOCR-VL实现全线SOTA,刷新全球OCR VL模型性能天花板。
摘要:百度在WAVE SUMMIT 2025大会上发布文心大模型X1.1深度思考模型,在事实性、指令遵循和智能体能力上分别提升34.8%、12.5%和9.6%。该模型采用迭代式混合强化学习框架,在多个评测中表现优异。同时发布的文心快码3.5S版本强化了多智能体协同能力,已服务超1000万开发者。百度还展示了剧本驱动多模协同的数字人技术,其直播表现超越真人,并推出"文心导师·星耀计划&qu

监督对比学习的目标是最大化正样本对(同一类别的样本)的一致性,并最小化负样本对(不同类别的样本)的一致性。监督对比损失通过鼓励正样本对的表示在嵌入空间中更加接近,同时将负样本对的表示推开来实现这一目标。对比损失:Supervised Contrastive Loss(监督对比损失)是一种在监督对比学习中使用的损失函数。它旨在学习既具有区分性又具有对同一类别内变化具有不变性的表示。

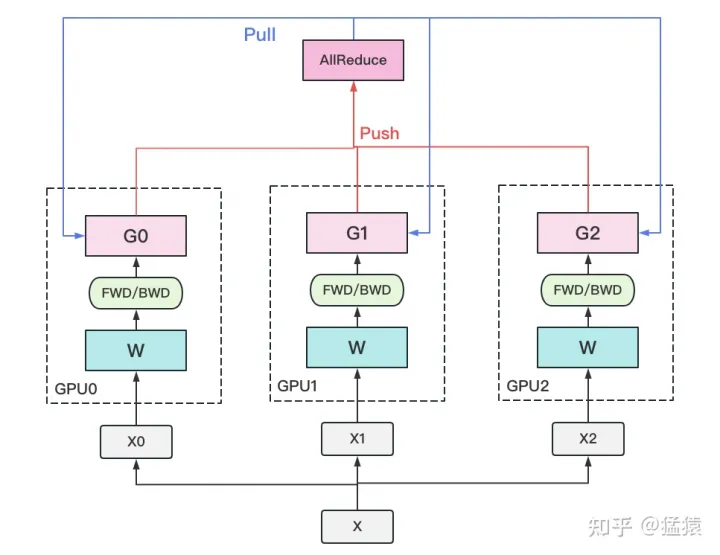
受通讯负载不均的影响,DP一般用于单机多卡场景。因此,DDP作为一种更通用的解决方案出现了,既能多机,也能单机。DDP首先要解决的就是通讯问题:将Server上的通讯压力均衡转到各个Worker上。实现这一点后,可以进一步去Server,留Worker。聚合梯度 + 下发梯度这一轮操作,称为AllReduce。接下来我们介绍目前最通用的AllReduce方法:Ring-AllReduce。它由百度
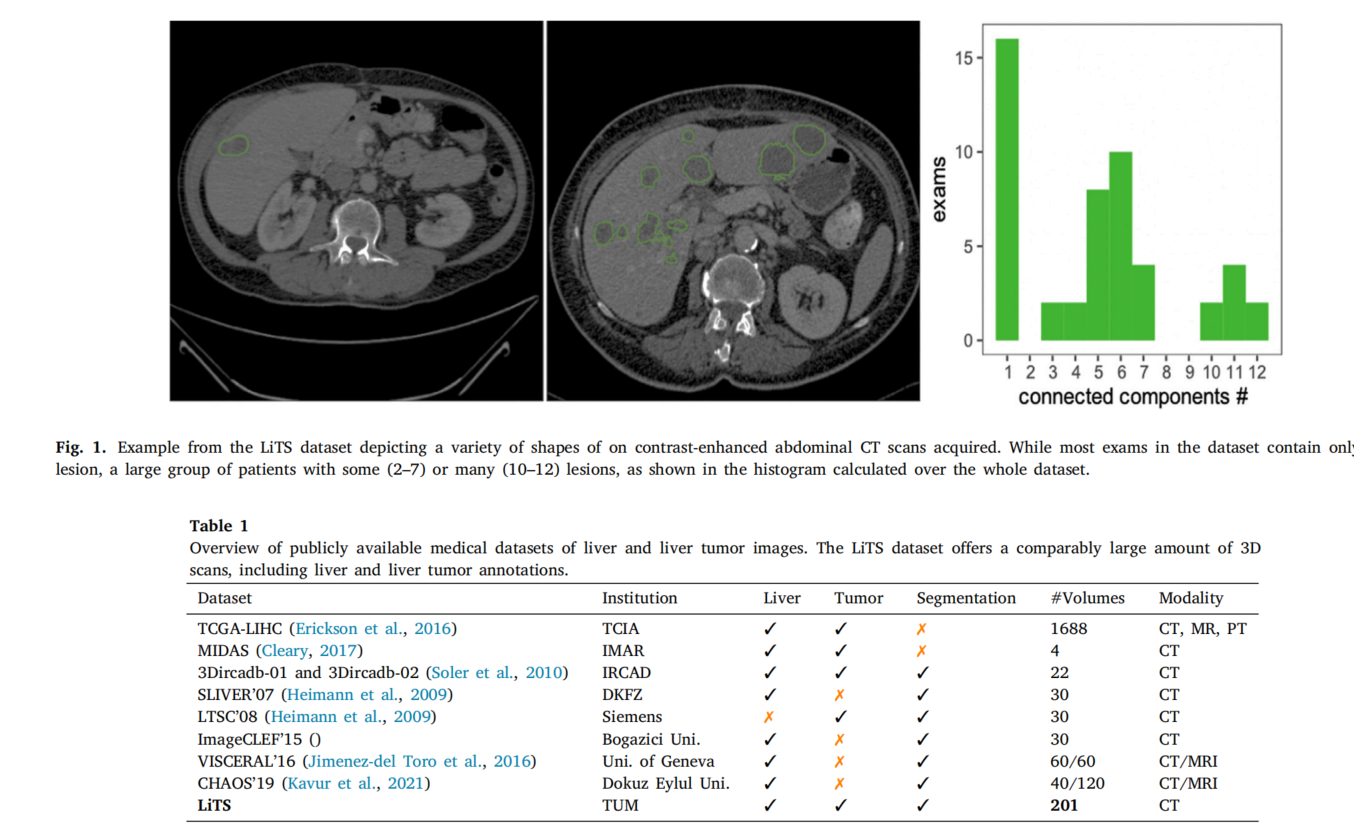
医疗图像分割LiTM数据集上的综述文章,总结性非常强,大佬的文章就是不一样,遣词造句就值得我学
具体来说,在助攻生成过程中,特定的助攻模型将返回模型的生成 output 或。函数负责执行不同的生成方法和逻辑以生成模型的输出。它允许用户根据实际需要执行不同的生成方法,并支持其他参数的进一步控制。这个函数给了人们灵活的选择,以获得满足需求的生成输出。函数根据模型的生成配置、输入和相应的参数调用相应的生成方法,包括模型的贪婪搜索、显示搜索、样本生成等。函数可以进入不同的生成模式和执行相应的生成方法

使用DeepSpeed时,首先需要提供一个ds_config文件然后参照上文基础用法,将model用deepspeed.initialize()包装起来deepspeed.initialize()内部会初始化通信,所以就不需要手动调用dist.init_process_group()了(当然也可以手动调用deepspeed.init_distributed()来初始化)

这种方法的好处是,你可以离线处理文章中的词等细粒度的向量表示,从而大大加速检索的效率(DR中,每拿到一个新的document,都需要将这个document进行向量化)。基于查询的RAG也被称为提示增强。然而,SR方面,ColBERT 或 AligneR 等后期交互模型试图通过计算每个token的向量,然后以某种方式利用它们,来减轻必须选择在固定大小的向量中出现的存储等的问题。在基于潜在表示的检索增
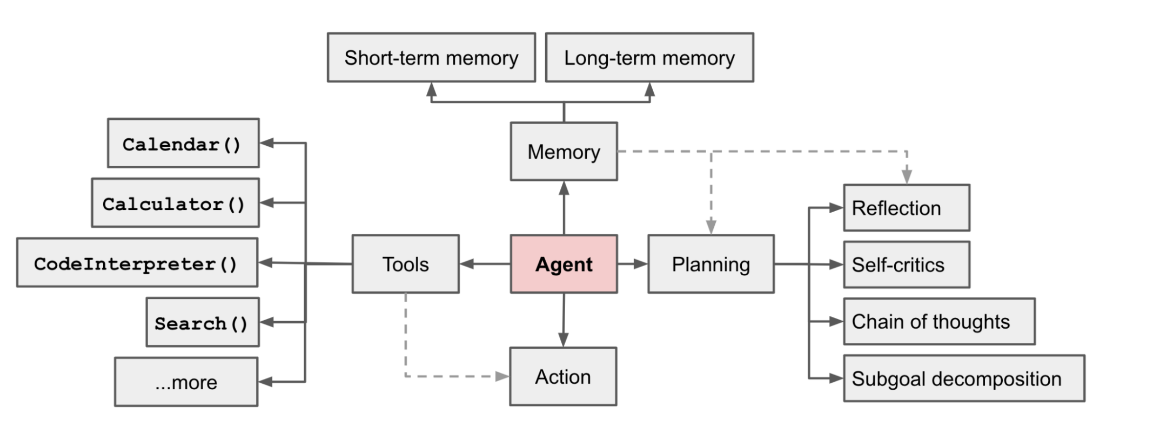
那么Agent又是什么?agent用来调用外部 API 来获取模型权重中缺失的额外信息(通常在预训练后很难更改),包括当前信息、代码执行能力、对专有信息源的访问等。