- @QingKeLab
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
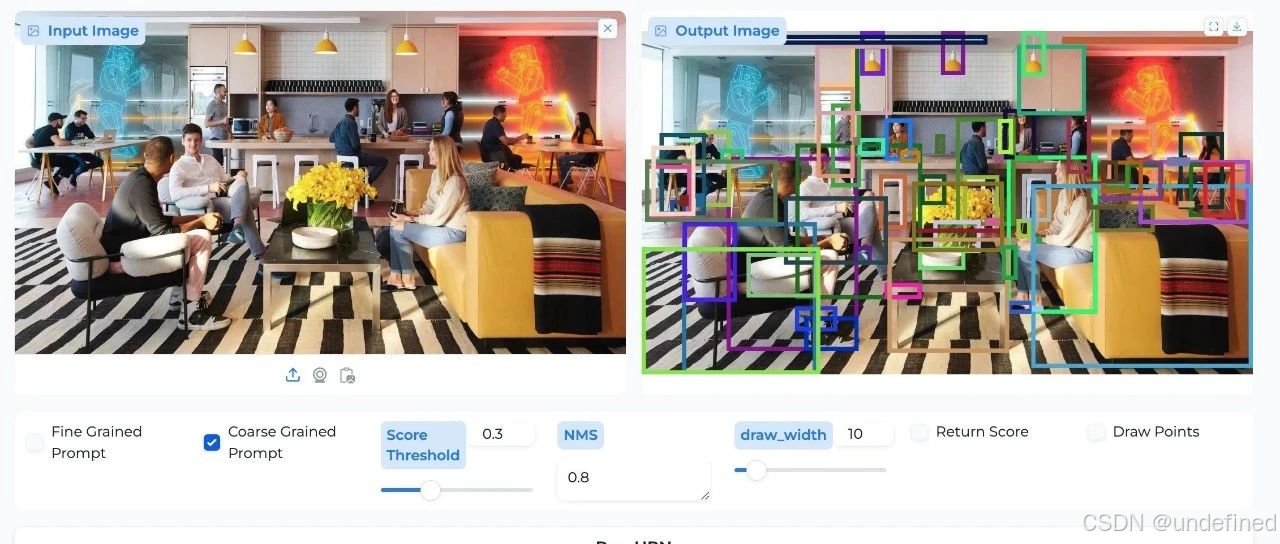
ChatRex、RexSeek 和 RexThinker,这三者分别代表着目标检测任务从自然语言理解、到指代消解、再到多模态推理能力的三次进化。
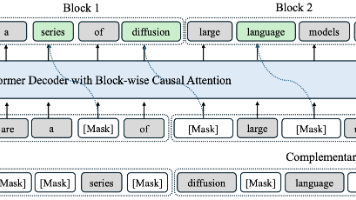
Fast-dLLM v2 旨在通过高效块扩散架构突破大模型推理的速度瓶颈。
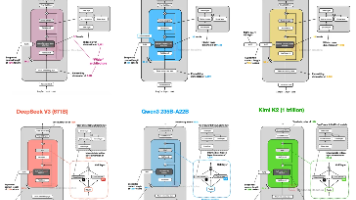
摘要: 本文对比了2025年主流大语言模型(LLM)的架构演进,聚焦于DeepSeek V3/R1和OLMo 2的关键创新。DeepSeek V3采用**多头潜在注意力(MLA)压缩KV缓存以提升推理效率,并通过混合专家(MoE)**架构(含共享专家)实现参数高效利用(6710亿参数中仅激活37亿)。OLMo 2则以其开源透明性著称,虽性能非顶尖但为LLM开发提供了清晰蓝图。文章指出,尽管近年模型
青稞Talk主页:qingkelab.github.io/talks所有直播回放:https://appodzjvyp51702.h5.xiaoeknow.com随着大语言模型的兴起,多模态大模型也取得了显著进步,推动了复杂的视觉语言对话和交互,弥合了文本与视觉信息之间的鸿沟。然而,现有的开源模型与商用闭源模型(如GPT-4o和Gemini 1.5 Pro)之间的能力差距仍然显著。InternVL
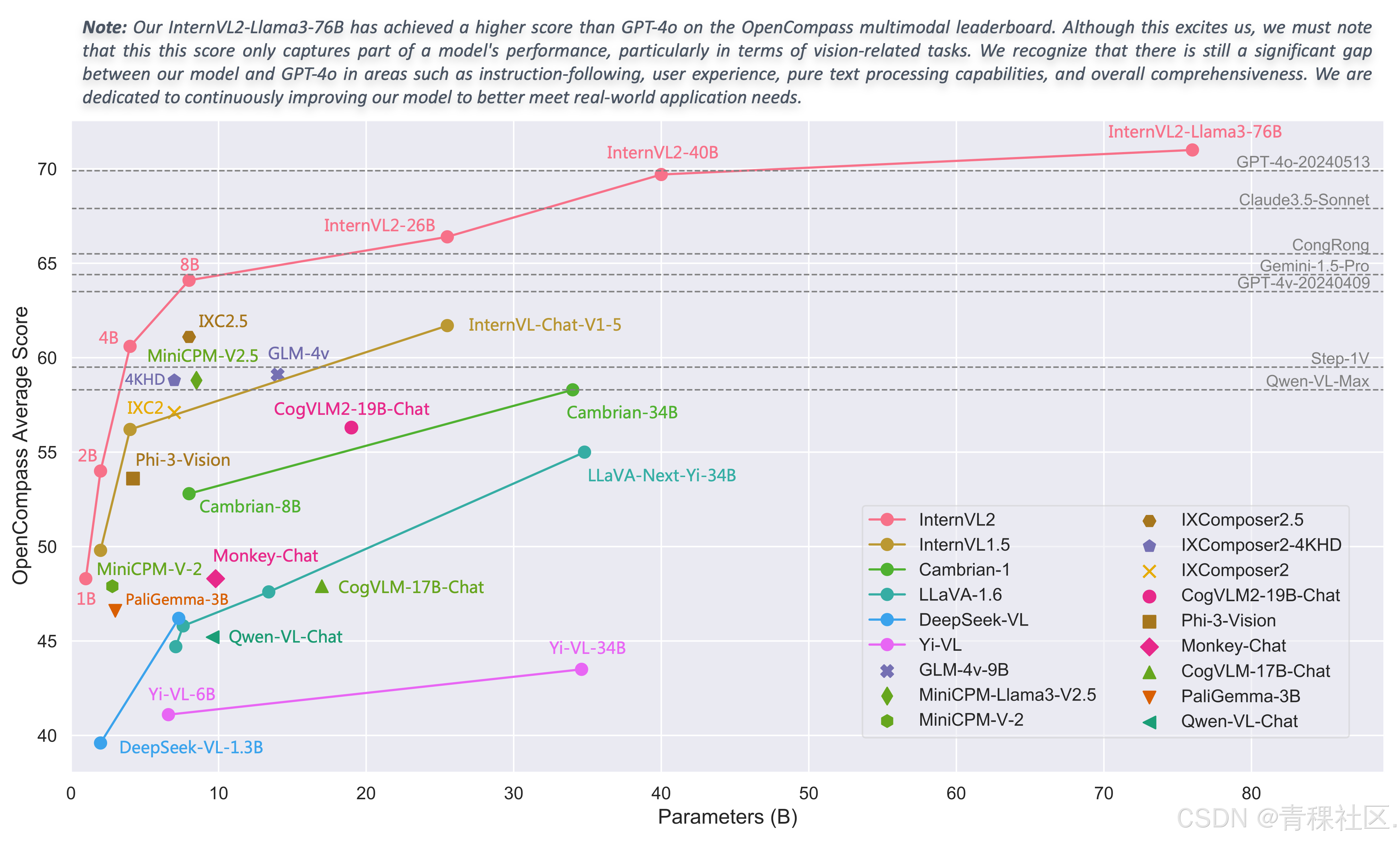
RTPurbo:基于原生稀疏性的高效大语言模型推理优化 摘要: 本文提出RTPurbo,一种通过轻量级微调激活大语言模型原生稀疏特性的高效推理优化方案。研究发现,经过Full Attention训练的模型在Head和Token级别已具备高度稀疏性:仅15%的Attention Head承担长程检索功能,且低频RoPE编码可构建极低维检索空间。RTPurbo通过离线Head校准、动态稀疏注意力机制和
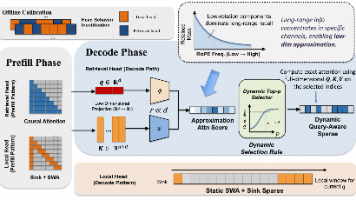
本文提出ZEDA方法,通过注入零专家和自蒸馏训练,将已训练好的MoE模型低成本迁移为动态MoE模型。核心创新包括:1)引入零专家作为跳过计算的选项;2)采用SFT+OPD两阶段自蒸馏适应新结构;3)设计分组辅助损失控制计算节省比例。实验表明,该方法能在跳过约50%专家计算的情况下,保持模型在数学推理、代码生成和指令遵循等任务上的性能仅小幅下降。相比直接修改路由或裁剪专家,ZEDA提供了一种更温和高
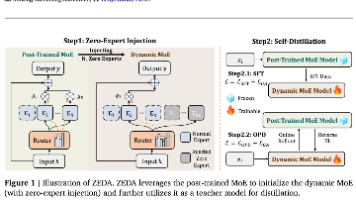
华东师范大学与复旦大学团队在ICLR 2026论文《Next-ToBE》中提出了一种创新的大语言模型训练方法。研究发现,当前模型预测分布中已隐含未来token信息,但标准next-token训练目标未能充分利用这一前瞻能力。Next-ToBE通过将单点one-hot标签扩展为覆盖未来窗口的软目标分布,在不改变模型结构的情况下激活了模型的潜在前瞻能力。实验表明,该方法在数学推理、代码生成等任务上显著
华东师范大学与复旦大学团队在ICLR 2026论文《Next-ToBE》中提出了一种创新的大语言模型训练方法。研究发现,当前模型预测分布中已隐含未来token信息,但标准next-token训练目标未能充分利用这一前瞻能力。Next-ToBE通过将单点one-hot标签扩展为覆盖未来窗口的软目标分布,在不改变模型结构的情况下激活了模型的潜在前瞻能力。实验表明,该方法在数学推理、代码生成等任务上显著
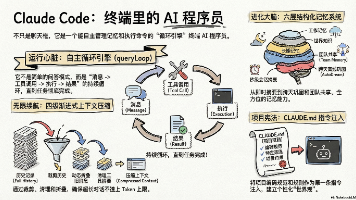
近 5 万字的claude code解析,55 张专业图表,基于扫描泄露的 Claude Code 50万行源码的系统性分析,帮助大家理解harness engineering。
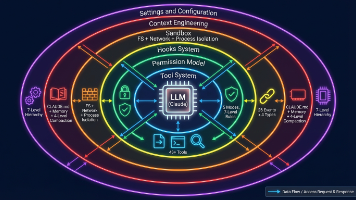
本文对Claude Code CLI工具的源码进行了深度解析,重点分析其核心运行机制和Memory模块设计。文章首先介绍了Claude Code作为Anthropic开发的命令行AI编程助手的技术栈(Bun/TypeScript/Commander.js等)和项目结构。随后详细阐述了其核心运行流程:从用户输入开始,通过QueryEngine管理对话状态,进入queryLoop()核心循环处理消息准