




- @Mr_wang_user
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
多头自注意力机制的核心思想是将输入序列分割成多个子空间,也可以理解为多“头”(heads),每个“头”独立地计算注意力,从而能够捕捉到输入序列中不同位置的特征和关系。,Multi-Head Latent Attention),主要优化的点在于:能够显著降低内存占用和计算开销,同时保持模型性能。DeepSeek使用的Transformer架构中,使用的是优化后的多头自注意力机制,名为。假如模型维度(

太阳能发电受天气、温度、光照强度等多种因素影响,具有间歇性和波动性,准确预测太阳能发电功率对于电网调度和能源管理至关重要。人工神经网络(ANN)由于其自适应、自学习和非线性映射能力,在太阳能发电预测中得到了广泛应用。本文将从神经网络的基本原理入手,逐步深入到其在太阳能发电预测中的应用,并以Matlab神经网络工具箱为例,展示如何利用神经网络构造预测模型。

太阳能发电受天气、温度、光照强度等多种因素影响,具有间歇性和波动性,准确预测太阳能发电功率对于电网调度和能源管理至关重要。人工神经网络(ANN)由于其自适应、自学习和非线性映射能力,在太阳能发电预测中得到了广泛应用。本文将从神经网络的基本原理入手,逐步深入到其在太阳能发电预测中的应用,并以Matlab神经网络工具箱为例,展示如何利用神经网络构造预测模型。
Deepseek提出了一种创新的注意力机制,名为多头潜在注意力(MLA,Multi-Head Latent Attention),是基于多头自注意力机制(MHA)的优化,能够显著降低内存占用和计算开销,同时保持模型性能。

多头自注意力机制的核心思想是将输入序列分割成多个子空间,也可以理解为多“头”(heads),每个“头”独立地计算注意力,从而能够捕捉到输入序列中不同位置的特征和关系。,Multi-Head Latent Attention),主要优化的点在于:能够显著降低内存占用和计算开销,同时保持模型性能。DeepSeek使用的Transformer架构中,使用的是优化后的多头自注意力机制,名为。假如模型维度(
代理是指 Deepseek、ChatGPT 等大模型能够自我构建解决一个特定任务的流程,以及自我决定在此过程中使用哪些工具。与之类似的还有一个名为工作流(workflows)的系统,工作流是指通过预先设计好的流程与工具来解决某个任务。两者的区别在于:代理可以自我动态调整,如设定一个任务让其完成,它能够自我决定整个工作流程,决定调用哪些工具,在出错时还能够自我修正,保证最终的任务能够顺利完成,更为灵
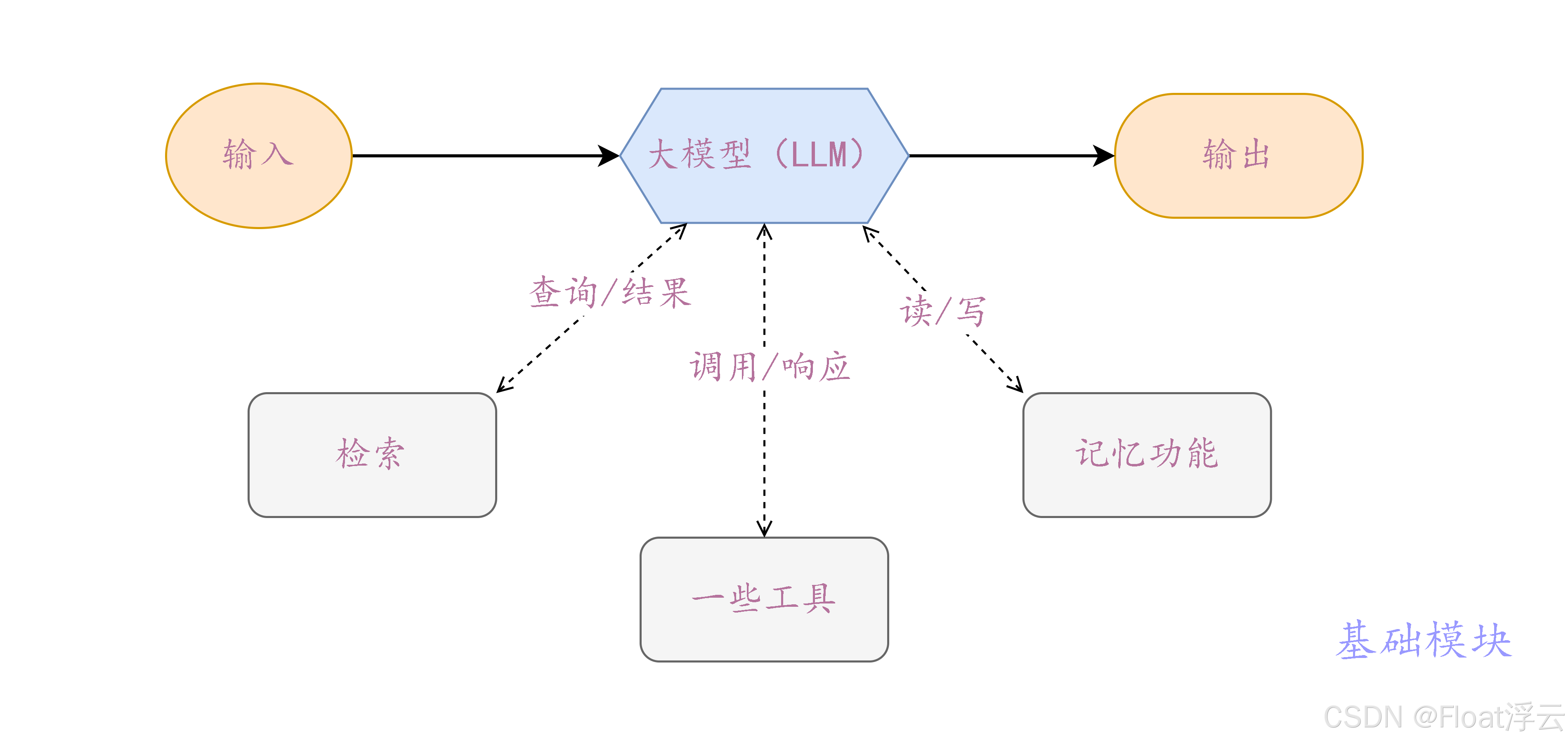
代理是指 Deepseek、ChatGPT 等大模型能够自我构建解决一个特定任务的流程,以及自我决定在此过程中使用哪些工具。与之类似的还有一个名为工作流(workflows)的系统,工作流是指通过预先设计好的流程与工具来解决某个任务。两者的区别在于:代理可以自我动态调整,如设定一个任务让其完成,它能够自我决定整个工作流程,决定调用哪些工具,在出错时还能够自我修正,保证最终的任务能够顺利完成,更为灵
Deepseek提出了一种创新的注意力机制,名为多头潜在注意力(MLA,Multi-Head Latent Attention),是基于多头自注意力机制(MHA)的优化,能够显著降低内存占用和计算开销,同时保持模型性能。
多头自注意力机制的核心思想是将输入序列分割成多个子空间,也可以理解为多“头”(heads),每个“头”独立地计算注意力,从而能够捕捉到输入序列中不同位置的特征和关系。,Multi-Head Latent Attention),主要优化的点在于:能够显著降低内存占用和计算开销,同时保持模型性能。DeepSeek使用的Transformer架构中,使用的是优化后的多头自注意力机制,名为。假如模型维度(